" height="2.0768733066194303px" id="D9zvikPGQ" transform="translate(2.998 0.199)" width="5.731236321640176px"/><path d="M 0.187 0.574 L 3.457 3.297 C 3.457 3.297 3.662 3.483 3.885 3.483 C 4.089 3.483 4.312 3.297 4.312 3.297 L 7.582 0.574 C 7.713 0.481 7.768 0.313 7.675 0.163 C 7.601 0.014 7.415 -0.042 7.267 0.033 L 4.182 2.103 L 3.903 2.271 C 3.885 2.271 3.847 2.271 3.81 2.271 L 3.531 2.103 L 0.447 0.033 C 0.298 -0.042 0.131 0.033 0.038 0.163 C -0.036 0.313 0.001 0.481 0.131 0.574 Z" fill="rgb(0, 0, 0)" height="3.483465559558452px" id="XHPDa9C06" transform="translate(1.975 1.124)" width="7.7215397232611345px"/><path d="M 1.933 5.727 C 2.063 5.652 2.1 5.503 2.044 5.372 L 0.966 2.91 C 0.966 2.892 0.966 2.873 0.966 2.854 L 2.044 0.392 C 2.1 0.262 2.044 0.113 1.933 0.038 C 1.803 -0.037 1.654 0.001 1.58 0.131 L 0.112 2.519 C 0.112 2.519 0 2.705 0 2.873 C 0 3.078 0.112 3.246 0.112 3.246 L 1.58 5.634 C 1.654 5.745 1.803 5.783 1.933 5.727 Z" fill="rgb(0, 0, 0)" height="5.752520201428617px" id="fSIVTyYyB" transform="translate(9.688 3.208)" width="2.0692037208998664px"/><path d="M 2.899 0.187 L 0.186 3.47 C 0.186 3.47 0 3.675 0 3.899 C 0 4.104 0.186 4.328 0.186 4.328 L 2.899 7.611 C 2.992 7.741 3.159 7.797 3.308 7.704 C 3.456 7.629 3.512 7.443 3.438 7.294 L 1.375 4.197 L 1.208 3.918 C 1.208 3.899 1.208 3.862 1.208 3.824 L 1.375 3.545 L 3.438 0.448 C 3.512 0.299 3.438 0.131 3.308 0.038 C 3.159 -0.037 2.992 0.001 2.899 0.131 Z" fill="rgb(0, 0, 0)" height="7.750209501286653px" id="XEy5_M_wF" transform="translate(7.365 2.182)" width="3.470578512630766px"/><path d="M 0.026 1.94 C 0.1 2.07 0.249 2.108 0.379 2.052 L 2.832 0.97 C 2.85 0.97 2.869 0.97 2.887 0.97 L 5.34 2.052 C 5.47 2.108 5.619 2.052 5.693 1.94 C 5.768 1.809 5.731 1.66 5.6 1.585 L 3.222 0.112 C 3.222 0.112 3.036 0 2.869 0 C 2.664 0 2.497 0.112 2.497 0.112 L 0.119 1.585 C 0.007 1.66 -0.03 1.809 0.026 1.94 Z" fill="rgb(0, 0, 0)" height="2.0768899917602535px" id="GVAyPotmc" transform="translate(3.029 9.923)" width="5.731234655014601px"/><path d="M 7.535 2.91 L 4.264 0.187 C 4.264 0.187 4.06 0 3.837 0 C 3.633 0 3.41 0.187 3.41 0.187 L 0.139 2.91 C 0.009 3.003 -0.047 3.171 0.046 3.32 C 0.12 3.469 0.306 3.525 0.455 3.451 L 3.54 1.38 L 3.818 1.212 C 3.837 1.212 3.874 1.212 3.911 1.212 L 4.19 1.38 L 7.275 3.451 C 7.423 3.525 7.591 3.451 7.684 3.32 C 7.758 3.171 7.721 3.003 7.591 2.91 Z" fill="rgb(0, 0, 0)" height="3.483478327665332px" id="UJGiliWlr" transform="translate(2.06 7.592)" width="7.721540951544936px"/><path d="M 0.137 0.026 C 0.007 0.1 -0.031 0.25 0.025 0.38 L 1.103 2.842 C 1.103 2.861 1.103 2.879 1.103 2.898 L 0.025 5.36 C -0.031 5.491 0.025 5.64 0.137 5.715 C 0.267 5.789 0.415 5.752 0.49 5.621 L 1.958 3.234 C 1.958 3.234 2.069 3.047 2.069 2.879 C 2.069 2.674 1.958 2.506 1.958 2.506 L 0.49 0.119 C 0.415 0.007 0.267 -0.03 0.137 0.026 Z" fill="rgb(0, 0, 0)" height="5.752526692867306px" id="DM37PXgJd" transform="translate(0 3.239)" width="2.0691900389284807px"/><path d="M 0.572 7.6 L 3.285 4.318 C 3.285 4.318 3.471 4.112 3.471 3.889 C 3.471 3.683 3.285 3.46 3.285 3.46 L 0.572 0.14 C 0.479 0.009 0.312 -0.047 0.163 0.046 C 0.014 0.121 -0.042 0.307 0.033 0.457 L 2.095 3.553 L 2.263 3.833 C 2.263 3.851 2.263 3.889 2.263 3.926 L 2.095 4.206 L 0.033 7.302 C -0.042 7.451 0.033 7.619 0.163 7.712 C 0.312 7.787 0.479 7.749 0.572 7.619 Z" fill="rgb(0, 0, 0)" height="7.750215230634018px" id="omz1nxiI6" transform="translate(0.922 2.23)" width="3.470588058544221px"/><path d="M 4.007 1.424 C 4.508 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.787 2.29 5.927 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.787 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.863 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.927 5.725 C 5.62 6.591 4.981 7.01 3.979 7.01 C 2.977 7.01 2.755 6.758 2.337 6.256 C 1.92 5.753 1.725 5.083 1.725 4.189 C 1.725 3.295 1.92 2.625 2.337 2.15 C 2.755 1.648 3.283 1.424 3.979 1.424 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="fGIMtJKmR" transform="translate(15.609 3.128)" width="7.735096310284753px"/><path d="M 6.093 0.503 C 5.481 0.168 4.814 0 4.034 0 C 3.255 0 2.532 0.168 1.92 0.531 C 1.308 0.866 0.835 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.529 6.423 C 0.89 7.066 1.363 7.568 1.976 7.903 C 2.588 8.267 3.283 8.434 4.062 8.434 C 4.841 8.434 5.815 8.183 6.455 7.708 C 7.095 7.233 7.54 6.619 7.791 5.865 L 5.982 5.865 C 5.62 6.619 4.98 7.01 4.062 7.01 C 3.144 7.01 2.894 6.814 2.476 6.423 C 2.031 6.032 1.809 5.502 1.753 4.859 L 7.958 4.859 C 7.985 4.608 8.013 4.329 8.013 4.022 C 8.013 3.24 7.846 2.541 7.512 1.927 C 7.179 1.313 6.706 0.838 6.121 0.503 Z M 1.725 3.491 C 1.809 2.849 2.059 2.346 2.476 1.983 C 2.894 1.62 3.395 1.424 3.979 1.424 C 4.563 1.424 5.147 1.62 5.593 1.983 C 6.038 2.346 6.26 2.849 6.26 3.491 L 1.753 3.491 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="qaL5FVZij" transform="translate(24.013 3.128)" width="8.01332295195354px"/><path d="M 5.815 0.391 C 5.314 0.112 4.73 0 4.09 0 C 3.45 0 3.144 0.084 2.727 0.279 C 2.309 0.475 1.948 0.726 1.669 1.061 L 1.669 0.14 L 0 0.14 L 0 8.294 L 1.669 8.294 L 1.669 3.742 C 1.669 3.016 1.864 2.458 2.226 2.067 C 2.587 1.676 3.088 1.48 3.729 1.48 C 4.368 1.48 4.841 1.676 5.231 2.067 C 5.592 2.458 5.787 3.016 5.787 3.742 L 5.787 8.294 L 7.457 8.294 L 7.457 3.491 C 7.457 2.737 7.318 2.122 7.04 1.592 C 6.761 1.061 6.344 0.67 5.843 0.419 Z" fill="rgb(0, 0, 0)" height="8.294435702953454px" id="WDjXqIjZT" transform="translate(33.166 3.128)" width="7.4567073744807075px"/><path d="M 2.643 0 L 0.946 0 L 0.946 2.039 L 0 2.039 L 0 3.407 L 0.946 3.407 L 0.946 7.931 C 0.946 8.741 1.141 9.3 1.558 9.663 C 1.948 10.026 2.532 10.193 3.311 10.193 L 4.647 10.193 L 4.647 8.797 L 3.617 8.797 C 3.283 8.797 3.033 8.741 2.894 8.602 C 2.755 8.462 2.671 8.239 2.671 7.931 L 2.671 3.407 L 4.647 3.407 L 4.647 2.039 L 2.671 2.039 L 2.671 0 Z" fill="rgb(0, 0, 0)" height="10.193494685087567px" id="nZ8KAi6H2" transform="translate(41.458 1.229)" width="4.646524285330045px"/><path d="M 1.085 0 C 0.779 0 0.528 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.095 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(0, 0, 0)" height="2.1783368721996954px" id="xofK7bnqV" transform="translate(47.384 0)" width="2.1424521645366994px"/><path d="M 1.669 0 L 0 0 L 0 8.155 L 1.669 8.155 Z" fill="rgb(0, 0, 0)" height="8.154788300335934px" id="owXtEW3wx" transform="translate(47.607 3.267)" width="1.6694896185170123px"/><path d="M 1.085 0 C 0.779 0 0.529 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.067 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(0, 0, 0)" height="2.1783368721996954px" id="qYXTLcef6" transform="translate(55.842 0)" width="2.1424521645367136px"/><path d="M 4.007 7.01 C 3.311 7.01 2.783 6.758 2.365 6.256 C 1.948 5.753 1.753 5.083 1.753 4.189 C 1.753 3.295 1.948 2.625 2.365 2.15 C 2.783 1.648 3.311 1.424 4.007 1.424 C 4.702 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.788 2.29 5.926 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.788 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.862 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.926 5.725 C 5.621 6.591 4.981 7.01 3.979 7.01 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="YVPoMPmqZ" transform="translate(59.265 3.128)" width="7.735226155870485px"/><path d="M 6.872 3.268 L 2.643 3.268 L 2.643 2.681 C 2.643 2.206 2.754 1.871 2.949 1.676 C 3.144 1.508 3.478 1.396 3.923 1.396 L 3.923 0 C 2.921 0 2.17 0.223 1.697 0.642 C 1.196 1.061 0.946 1.759 0.946 2.681 L 0.946 3.268 L 0 3.268 L 0 4.636 L 0.946 4.636 L 0.946 11.422 L 2.643 11.422 L 2.643 4.636 L 5.203 4.636 L 5.203 11.422 L 6.872 11.422 Z" fill="rgb(0, 0, 0)" height="11.422308710362525px" id="mR0Sii5R7" transform="translate(50.863 0)" width="6.872402238697973px"/></g></svg>)
" width="11.757210121961878px"><path d="M 5.706 0.137 C 5.631 0.007 5.483 -0.031 5.353 0.025 L 2.9 1.107 C 2.881 1.107 2.862 1.107 2.844 1.107 L 0.391 0.025 C 0.261 -0.031 0.112 0.025 0.038 0.137 C -0.036 0.268 0.001 0.417 0.131 0.491 L 2.509 1.965 C 2.509 1.965 2.695 2.077 2.862 2.077 C 3.067 2.077 3.234 1.965 3.234 1.965 L 5.613 0.491 C 5.724 0.417 5.761 0.268 5.706 0.137 Z" fill="rgb(255, 255, 255)" height="2.0768733060957265px" id="JOqgQgeXH" transform="translate(2.998 0)" width="5.731236321640178px"/><path d="M 0.187 0.574 L 3.457 3.297 C 3.457 3.297 3.662 3.483 3.885 3.483 C 4.089 3.483 4.312 3.297 4.312 3.297 L 7.582 0.574 C 7.713 0.481 7.768 0.313 7.675 0.163 C 7.601 0.014 7.415 -0.042 7.267 0.033 L 4.182 2.103 L 3.903 2.271 C 3.885 2.271 3.847 2.271 3.81 2.271 L 3.531 2.103 L 0.447 0.033 C 0.298 -0.042 0.131 0.033 0.038 0.163 C -0.036 0.313 0.001 0.481 0.131 0.574 Z" fill="rgb(255, 255, 255)" height="3.483465570588767px" id="Zd5XdemVt" transform="translate(1.975 0.925)" width="7.721539723261137px"/><path d="M 1.933 5.727 C 2.063 5.652 2.1 5.503 2.044 5.372 L 0.966 2.91 C 0.966 2.892 0.966 2.873 0.966 2.854 L 2.044 0.392 C 2.1 0.262 2.044 0.113 1.933 0.038 C 1.803 -0.037 1.654 0.001 1.58 0.131 L 0.112 2.519 C 0.112 2.519 0 2.705 0 2.873 C 0 3.078 0.112 3.246 0.112 3.246 L 1.58 5.634 C 1.654 5.745 1.803 5.783 1.933 5.727 Z" fill="rgb(255, 255, 255)" height="5.752520201428616px" id="wm4QOyIBO" transform="translate(9.688 3.009)" width="2.069203720899866px"/><path d="M 2.899 0.187 L 0.186 3.47 C 0.186 3.47 0 3.675 0 3.899 C 0 4.104 0.186 4.328 0.186 4.328 L 2.899 7.611 C 2.992 7.741 3.159 7.797 3.308 7.704 C 3.456 7.629 3.512 7.443 3.438 7.294 L 1.375 4.197 L 1.208 3.918 C 1.208 3.899 1.208 3.862 1.208 3.824 L 1.375 3.545 L 3.438 0.448 C 3.512 0.299 3.438 0.131 3.308 0.038 C 3.159 -0.037 2.992 0.001 2.899 0.131 Z" fill="rgb(255, 255, 255)" height="7.750209542168115px" id="Tb0_95onW" transform="translate(7.365 1.983)" width="3.470578512630766px"/><path d="M 0.026 1.94 C 0.1 2.07 0.249 2.108 0.379 2.052 L 2.832 0.97 C 2.85 0.97 2.869 0.97 2.887 0.97 L 5.34 2.052 C 5.47 2.108 5.619 2.052 5.693 1.94 C 5.768 1.809 5.731 1.66 5.6 1.585 L 3.222 0.112 C 3.222 0.112 3.036 0 2.869 0 C 2.664 0 2.497 0.112 2.497 0.112 L 0.119 1.585 C 0.007 1.66 -0.03 1.809 0.026 1.94 Z" fill="rgb(255, 255, 255)" height="2.07689008196461px" id="mLkmMllwc" transform="translate(3.029 9.724)" width="5.731234655014603px"/><path d="M 7.535 2.91 L 4.264 0.187 C 4.264 0.187 4.06 0 3.837 0 C 3.633 0 3.41 0.187 3.41 0.187 L 0.139 2.91 C 0.009 3.003 -0.047 3.171 0.046 3.32 C 0.12 3.469 0.306 3.525 0.455 3.451 L 3.54 1.38 L 3.818 1.212 C 3.837 1.212 3.874 1.212 3.911 1.212 L 4.19 1.38 L 7.275 3.451 C 7.423 3.525 7.591 3.451 7.684 3.32 C 7.758 3.171 7.721 3.003 7.591 2.91 Z" fill="rgb(255, 255, 255)" height="3.483478327665331px" id="r0d9h4JTL" transform="translate(2.06 7.392)" width="7.7215409515449345px"/><path d="M 0.137 0.026 C 0.007 0.1 -0.031 0.25 0.025 0.38 L 1.103 2.842 C 1.103 2.861 1.103 2.879 1.103 2.898 L 0.025 5.36 C -0.031 5.491 0.025 5.64 0.137 5.715 C 0.267 5.789 0.415 5.752 0.49 5.621 L 1.958 3.234 C 1.958 3.234 2.069 3.047 2.069 2.879 C 2.069 2.674 1.958 2.506 1.958 2.506 L 0.49 0.119 C 0.415 0.007 0.267 -0.03 0.137 0.026 Z" fill="rgb(255, 255, 255)" height="5.752526692867306px" id="yi3WcGLKq" transform="translate(0 3.04)" width="2.0691900389284807px"/><path d="M 0.572 7.6 L 3.285 4.318 C 3.285 4.318 3.471 4.112 3.471 3.889 C 3.471 3.683 3.285 3.46 3.285 3.46 L 0.572 0.14 C 0.479 0.009 0.312 -0.047 0.163 0.046 C 0.014 0.121 -0.042 0.307 0.033 0.457 L 2.095 3.553 L 2.263 3.833 C 2.263 3.851 2.263 3.889 2.263 3.926 L 2.095 4.206 L 0.033 7.302 C -0.042 7.451 0.033 7.619 0.163 7.712 C 0.312 7.787 0.479 7.749 0.572 7.619 Z" fill="rgb(255, 255, 255)" height="7.750215283552243px" id="p6XslZnAU" transform="translate(0.922 2.031)" width="3.4705880585442213px"/></g><path d="M 4.007 1.424 C 4.508 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.787 2.29 5.927 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.787 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.863 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.927 5.725 C 5.62 6.591 4.981 7.01 3.979 7.01 C 2.977 7.01 2.755 6.758 2.337 6.256 C 1.92 5.753 1.725 5.083 1.725 4.189 C 1.725 3.295 1.92 2.625 2.337 2.15 C 2.755 1.648 3.283 1.424 3.979 1.424 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="d2DNCsqwq" transform="translate(15.609 3.128)" width="7.735096310284753px"/><path d="M 6.093 0.503 C 5.481 0.168 4.814 0 4.034 0 C 3.255 0 2.532 0.168 1.92 0.531 C 1.308 0.866 0.835 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.529 6.423 C 0.89 7.066 1.363 7.568 1.976 7.903 C 2.588 8.267 3.283 8.434 4.062 8.434 C 4.841 8.434 5.815 8.183 6.455 7.708 C 7.095 7.233 7.54 6.619 7.791 5.865 L 5.982 5.865 C 5.62 6.619 4.98 7.01 4.062 7.01 C 3.144 7.01 2.894 6.814 2.476 6.423 C 2.031 6.032 1.809 5.502 1.753 4.859 L 7.958 4.859 C 7.985 4.608 8.013 4.329 8.013 4.022 C 8.013 3.24 7.846 2.541 7.512 1.927 C 7.179 1.313 6.706 0.838 6.121 0.503 Z M 1.725 3.491 C 1.809 2.849 2.059 2.346 2.476 1.983 C 2.894 1.62 3.395 1.424 3.979 1.424 C 4.563 1.424 5.147 1.62 5.593 1.983 C 6.038 2.346 6.26 2.849 6.26 3.491 L 1.753 3.491 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="NZQSgmK3B" transform="translate(24.013 3.128)" width="8.01332295195354px"/><path d="M 5.815 0.391 C 5.314 0.112 4.73 0 4.09 0 C 3.45 0 3.144 0.084 2.727 0.279 C 2.309 0.475 1.948 0.726 1.669 1.061 L 1.669 0.14 L 0 0.14 L 0 8.294 L 1.669 8.294 L 1.669 3.742 C 1.669 3.016 1.864 2.458 2.226 2.067 C 2.587 1.676 3.088 1.48 3.729 1.48 C 4.368 1.48 4.841 1.676 5.231 2.067 C 5.592 2.458 5.787 3.016 5.787 3.742 L 5.787 8.294 L 7.457 8.294 L 7.457 3.491 C 7.457 2.737 7.318 2.122 7.04 1.592 C 6.761 1.061 6.344 0.67 5.843 0.419 Z" fill="rgb(255, 255, 255)" height="8.294435702953454px" id="y4C5qOSA0" transform="translate(33.166 3.128)" width="7.4567073744807075px"/><path d="M 2.643 0 L 0.946 0 L 0.946 2.039 L 0 2.039 L 0 3.407 L 0.946 3.407 L 0.946 7.931 C 0.946 8.741 1.141 9.3 1.558 9.663 C 1.948 10.026 2.532 10.193 3.311 10.193 L 4.647 10.193 L 4.647 8.797 L 3.617 8.797 C 3.283 8.797 3.033 8.741 2.894 8.602 C 2.755 8.462 2.671 8.239 2.671 7.931 L 2.671 3.407 L 4.647 3.407 L 4.647 2.039 L 2.671 2.039 L 2.671 0 Z" fill="rgb(255, 255, 255)" height="10.193494685087567px" id="HConpA1k2" transform="translate(41.458 1.229)" width="4.646524285330045px"/><path d="M 1.085 0 C 0.779 0 0.528 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.095 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(255, 255, 255)" height="2.1783368721996954px" id="EuoH5GVjb" transform="translate(47.384 0)" width="2.1424521645366994px"/><path d="M 1.669 0 L 0 0 L 0 8.155 L 1.669 8.155 Z" fill="rgb(255, 255, 255)" height="8.154788300335934px" id="zg308Vtf3" transform="translate(47.607 3.267)" width="1.6694896185170123px"/><path d="M 1.085 0 C 0.779 0 0.529 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.067 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(255, 255, 255)" height="2.1783368721996954px" id="SaMxhxR35" transform="translate(55.842 0)" width="2.1424521645367136px"/><path d="M 4.007 7.01 C 3.311 7.01 2.783 6.758 2.365 6.256 C 1.948 5.753 1.753 5.083 1.753 4.189 C 1.753 3.295 1.948 2.625 2.365 2.15 C 2.783 1.648 3.311 1.424 4.007 1.424 C 4.702 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.788 2.29 5.926 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.788 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.862 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.926 5.725 C 5.621 6.591 4.981 7.01 3.979 7.01 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="HetImuuV4" transform="translate(59.265 3.128)" width="7.735226155870485px"/><path d="M 6.872 3.268 L 2.643 3.268 L 2.643 2.681 C 2.643 2.206 2.754 1.871 2.949 1.676 C 3.144 1.508 3.478 1.396 3.923 1.396 L 3.923 0 C 2.921 0 2.17 0.223 1.697 0.642 C 1.196 1.061 0.946 1.759 0.946 2.681 L 0.946 3.268 L 0 3.268 L 0 4.636 L 0.946 4.636 L 0.946 11.422 L 2.643 11.422 L 2.643 4.636 L 5.203 4.636 L 5.203 11.422 L 6.872 11.422 Z" fill="rgb(255, 255, 255)" height="11.422308710362525px" id="Xc4NeSznw" transform="translate(50.863 0)" width="6.872402238697973px"/></g></svg>)


23 min read time
AI Summary by Centific
Turn this article into insights
with AI-powered summaries
Topics

Centific Physical AI Center of Excellence
The humanoid robotics race is accelerating. but much of the industry is optimizing for demonstration rather than deployment. Teleoperated humanoids make compelling marketing moments, yet they are not autonomous, resilient, or safe enough for real production environments.
Building a robot is no longer the hardest part. Training it to perform real work, safely and reliably, is where progress still stalls.
Across CES 2026 and similar showcases, dozens of humanoid robots have demonstrated impressive mobility. They have walked across stages, carried boxes, and completed carefully choreographed tasks. Those demonstrations are technically impressive, but they obscure a deeper truth: the gap between a humanoid that moves and a humanoid that is useful remains enormous.
The bottleneck is not hardware. It is not even an algorithm. The problem is the absence of large-scale, high-quality training data for real-world physical interaction with people.
Why This Matters Now
The urgency around humanoid robotics results from several technological trends converging at the same time:
Humanoid hardware is finally reaching practical maturity. Advances in actuators, sensors, and control systems mean robots can now move with stability and dexterity that was difficult even a decade ago.
Simulation platforms are scaling robot training. Tools like NVIDIA Isaac Sim allow researchers to generate thousands of training scenarios, enabling robots to practice tasks in virtual environments before deployment.
Robot foundation models are emerging. Models such as NVIDIA GR00T and other vision-language-action architectures provide a starting point for learning general robot behaviors across different embodiments.
These developments make large-scale humanoid deployment technically plausible for the first time.
But without massive real-world training datasets, humanoid robots will remain impressive demonstrations rather than reliable systems capable of operating in real environments.
The uncomfortable truth about humanoid AI
Watch humanoid demos closely. The robots are walking, picking up objects, or manipulating rigid items in controlled environments through teleoperation. Occasionally, a deformable task appears, such as folding a towel, but only under ideal conditions.
Simple objects like apples and tennis balls see near-100% success rates; complex tools like screwdrivers and scissors drop to around 30%.
We do not need humanoid robots to compose music, generate art, cook our meals, or brew our morning coffee. AI systems that live entirely in software already do those things and will soon do more.
Humanoids exist to do what humans cannot or should not do
Humanoid robots are not meant for novelty tasks. Their real purpose lies in the work that breaks bodies, the environments too toxic, too hot, or too confined for a person to safely enter, and the precision jobs that demand hours of sustained force control without fatigue. Much of this work remains dangerous today, contributing to hundreds of thousands of injuries each year because there has been no viable alternative.
Think of the electrician re-entering a live panel after a near-miss. The pipefitter working in a confined space with inches of clearance and zero ventilation. The wildland firefighter cutting containment lines while the fire roars uphill. The nuclear plant technician handling material that will remain lethal for a thousand years.
These are the tasks humanoids must learn to perform.
Now consider tasks that matter in real deployments. Would you trust humanoid robots to assist with airport security screening, support a clinician during a medical procedure, or help an elderly person stand up safely after a fall?
Those scenarios require sustained physical contact with humans, precise force control, real-time adaptation, and judgment under uncertainty. Today’s humanoids are far from meeting those requirements.
The distance between a humanoid and a useful humanoid is measured in millions of training examples that do not yet exist.
The robotics training data problem nobody wants to talk about
Physical AI faces a constraint that language and vision AI have not. Large language models have been trained on the written output of humanity with trillions of words, scraped, aggregated, and refined. Visual models have been trained with images captured and labeled over decades. Physical AI training data does not exist on the internet.
Humanoid robots require synchronized streams of vision, depth, force, torque, and tactile feedback, captured at millisecond precision while actions are performed in the physical world. They require accurate action trajectories, recovery behaviors, and exposure to failure. None of this can be scraped or cheaply generated.
Every meaningful demonstration must be collected deliberately, in real environments, one episode at a time. As Joy Yang argues in The Strange Review (March 2026), the hand has become the gating constraint for the entire humanoid industry. That gap is a training data problem, not primarily a hardware problem.

This is why NVIDIA, Meta, Google, Stanford, and major robotics labs are building data collection infrastructures. As robotics shifts from programmed robots to learning-based systems, training data becomes the obstacle and the key competitive differentiator.
The scale of the problem
The imbalance between digital AI data and physical AI data is stark. Language models trained on trillions of tokens. Vision systems learned from billions of images. Robot learning datasets remain comparatively microscopic.
Dataset | Scale |
DROID (2024) | 76K trajectories, 564 scenes |
Open X-Embodiment / RT-X (2023) | ~1M trajectories, 22 robot embodiments |
BEHAVIOR-1K (2024) | 1,000 household activities (primarily simulation) |
RoboTurk (2019) | Crowdsourced demos, limited scaling |
GPT-4 Training Text | 45 TB — the comparison that reveals the gap |
The world’s robot learning datasets contain perhaps a few million demonstrations. Compare that to the 45TB of text data used to train GPT-4.
Put another way: we’re trying to teach robots to navigate the physical world with 0.0001% of the data we used to teach AI to write emails.
That is why progress can look impressive in demos and still feel fragile in anything resembling deployment.
The industrial skills gap: factory SOPs, electricians, and the trades datasets nobody is building
Industrial environments reveal another side of the training problem: vast amounts of operational knowledge exist, but almost none of it is captured in a format robots can learn from.
The humanoid robot conversation is dominated by warehouses and household tasks. But some of the highest-value deployment environments for humanoid robots are industrial settings where skilled trades operate: electrical panels, HVAC systems, manufacturing lines, and process facilities. These environments have something most robot training pipelines lack entirely: decades of written standard operating procedures (SOPs), safety protocols, and task breakdowns developed for human workers. The challenge is that this institutional knowledge has never been translated into the multimodal, action-labeled format that physical AI requires.
Factory SOPs as latent training signal
Manufacturing facilities have accumulated SOPs over decades. A tier-1 automotive supplier may have thousands of work instructions covering torque sequences, inspection checkpoints, tool changeovers, and lockout/tagout procedures. A semiconductor fab has processed recipes specifying exact motion paths for wafer handling with sub-millimeter tolerances. These documents encode physical task knowledge at a level of detail that no internet-scraped dataset can replicate.
The gap is that SOPs describe what to do in text, not how to do it in motion. Bridging that gap requires pairing each SOP step with teleoperated demonstrations, synchronized sensor streams, and—critically—recovery demonstrations for when the step goes wrong. A torque sequence that assumes nominal bolt seating requires a very different training signal when a fastener cross-threads. Organizations sitting on large SOP libraries have a significant and largely untapped foundation for robot training data, but only if they invest in the collection infrastructure to activate it.
Carpentry and construction trades
Carpentry presents a microcosm of everything that makes skilled-trade data collection hard: material variability, tool diversity, force-dependent outcomes, and judgment calls that experienced craftspeople make instinctively but rarely articulate. A carpenter sizing a mortise-and-tenon joint applies different chisel pressure depending on wood grain orientation. This judgment takes years of tactile experience to internalize. No text SOP has ever captured that experience.
The electrician problem: dexterity, judgment, and situational variability
Electrical trades represent one of the most robotics-relevant skilled labor categories, and one of the most data-scarce. An electrician performing a panel termination must strip wire to a precise length, identify conductor gauge by feel and visual inspection, route cables through conduit without damaging insulation, and torque terminals to spec, all while reading a wiring diagram, navigating a live panel safely, and adapting to non-standard installations that differ from every blueprint. This is a task requiring tool manipulation, force control, visual reasoning, procedural memory, and in-context judgment. No public dataset covers it at scale.
The same pattern applies across the skilled trades. An HVAC technician diagnosing a refrigerant leak must reason from sensor readings, visual inspection, and past failure patterns simultaneously. A pipefitter positioning a joint must account for thermal expansion, alignment tolerances, and access constraints in the same motion sequence. These tasks share a common structure: they are procedurally defined but situationally variable. The SOP tells you the steps. The craftsperson tells you how to execute them under real conditions. Capturing the gap between the written procedure and the physical execution is exactly what robot training data must do, and it requires collecting demonstrations from skilled workers in the field, not just in labs.
What an industrial robotics dataset requires
Building an industrial robotics dataset differs from typical robot learning data collection in several dimensions that are rarely discussed. Tool interactions are a primary challenge: unlike pick-and-place with unpowered objects, industrial tasks involve powered tools, calibrated instruments, and specialized end-effectors.
Each introduces its own force-feedback signature and failure mode. A torque wrench that slips off a fastener head, a wire stripper that nicks insulation, a multimeter probe that contacts the wrong terminal are the most consequential recovery scenarios, and they are exactly what a lab demonstration cannot reproduce. Worker expertise becomes a data quality variable. A journeyman electrician and an apprentice will execute the same panel termination with measurably different motion profiles, force application, and error correction strategies. Capturing expertise gradients, not just successful completions, produces richer training signals.
Site variability is the third dimension. Industrial environments are not static. Conduit runs differ between buildings. Panel configurations deviate from drawings. Ambient temperature affects material compliance.
A useful industrial dataset must span real sites, not just representative mockups. NVIDIA’s Omniverse NuRec addresses part of this by enabling rapid photorealistic reconstruction of real facilities from photo captures. But visual fidelity alone does not capture the contact physics variation that industrial task recovery depends on.
The skilled trades are facing a generational workforce gap. In the United States alone, the electrical industry is projected to need hundreds of thousands of additional workers over the next decade as experienced tradespeople retire. Robotics is part of the long-term answer. But robots cannot perform work they were never trained on. Bridging the data gap for industrial tasks requires partnerships between robotics labs, trades training programs, and the companies that employ skilled workers. And it requires building that data infrastructure now, before deployment timelines make the gap impossible to close.
What “difficult” means
The difference between demonstration and deployment becomes clearer when we look at tasks that must work in real-world conditions.
Security screening: the ultimate stress test
Consider the challenge of training a humanoid to assist with TSA-style security screening. Not replacing human officers but augmenting them. Handling the repetitive physical aspects while humans focus on judgment calls.
This is an active area of development. And it’s extraordinarily difficult.
A screening action requires:
Contact force modulation: 2-5 Newtons of pressure, enough to detect concealed objects, not enough to cause discomfort
14 body zones covered systematically while respecting prohibited areas
Multi-modal perception: visual (passenger pose, clothing folds), tactile (12,000+ sensor readings/second), force/torque (six-axis feedback)
Real-time adaptation: passengers breathe, shift, tense up. The robot must maintain appropriate contact through continuous movement
Edge case detection: distinguish between a metal chain, a prosthetic limb, a concealed weapon, and an insulin pump
Force tolerance: ±0.5N. One wrong calibration and you've either missed a threat or caused a complaint. Where do you get 50,000 demonstrations of this task with synchronized multi-modal sensor data?
Medical assistance: force-sensitive human contact
The Surgie project at UC San Diego (Atar et al., 2025) has demonstrated humanoid teleoperation for medical procedures like ultrasound guidance, emergency airway management, and physical examinations. Their findings reveal both promise and sobering reality.
The Unitree G1 humanoid, controlled via bimanual teleoperation, successfully positioned ultrasound probes with appropriate pressure, assisted with bag-valve-mask (BVM) ventilation, and performed basic needle insertion tasks
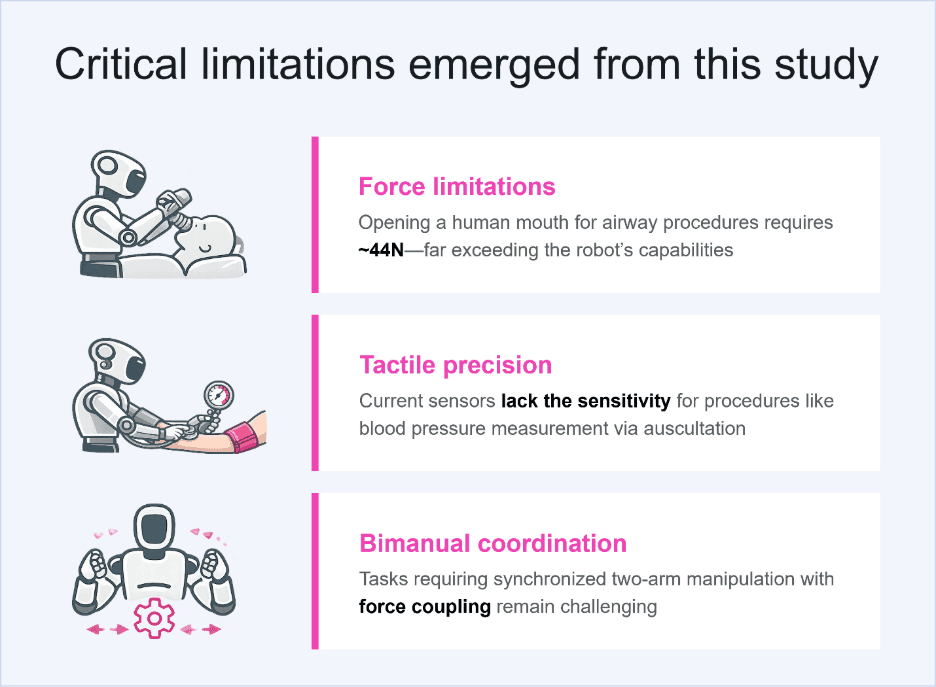
Critical limitations emerged from this study:
Force limitations: Opening a human mouth for airway procedures requires ~44N—far exceeding the robot’s capabilities
Tactile precision: current sensors lack the sensitivity for procedures like blood pressure measurement via auscultation
Bimanual coordination: tasks requiring synchronized two-arm manipulation with force coupling remain challenging
As Professor Michael Yip argues in Science Robotics (July 2025): “The scale of data required to train a truly capable AI to perform surgery with today’s robots would be too labor-intensive and cost-prohibitive with existing platforms.”
If humanoid robots in industrial settings can build strong AI foundation models through massive data collection, those capabilities could transfer to medical settings. A robot that learns to fold towels with two hands is learning bimanual coordination—the same fundamental skill needed to hold an ultrasound probe while inserting a needle.
Household manipulation: the deceptively simple
Folding a towel seems simple. It’s not. Consider:
Deformable object manipulation: fabric doesn't have a fixed shape. Every fold changes the state space
Bimanual coordination: two arms must work in concert with precise timing
Visual occlusion: one hand often blocks the camera’s view of what the other hand is doing
Recovery from failure: a bunched towel requires unfolding and restarting, not just “trying again.”
The BEHAVIOR-1K benchmark includes 1,000 household activities, from “clean a bathroom” to “pack a suitcase.” These aren’t single actions; they’re long-horizon tasks requiring dozens of coordinated sub-actions, each of which needs its own training data.
Eldercare: stakes higher than warehouse picking
When a robot assists an elderly person in standing up from a chair, the force profile must be precisely calibrated:
Too little support, and the person falls
Too much force results in injury, bruising, fear
Wrong timing results in loss of balance
Wrong contact points cause discomfort or harm
And unlike a warehouse where a dropped package means a dented box, a fall can mean a broken hip, hospitalization, or worse.
The regulatory and liability landscape for human-contact robotics is still being written. TSA/FAA/IATA have no established framework for robotic security screening. FDA pathways for humanoid medical assistants are undefined. Technology is advancing faster than governance.
The training stack for real-world tasks
Across security, healthcare, household assistance, and eldercare, a consistent pattern emerges. Useful humanoid behavior requires more than motion. It requires perception, force control, anticipation, recovery, and governance working together as a system.
This is why isolated demos do not translate into deployable capability. The challenge is not performing a task once. It is performing it safely, repeatedly, across people, environments, and edge cases. Here’s what works for training humanoids on complex, contact-rich, judgment-intensive tasks:
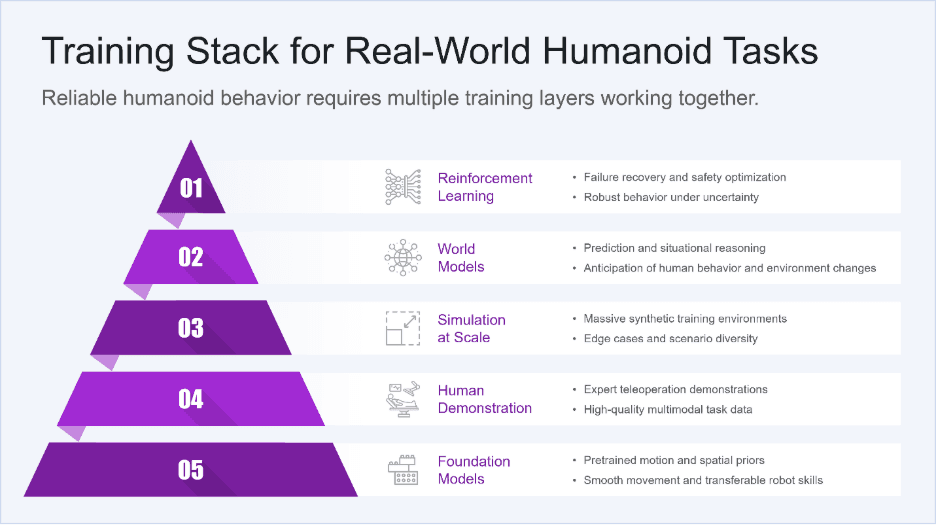
Layer 1: foundation models (the starting point)
You don’t train from scratch. Foundation models like NVIDIA GR00T provide humanoid motion priors learned from 100+ different robot embodiments. This gives you:
Smooth, natural-looking movement
Basic spatial reasoning
Transfer learning from millions of existing demonstrations
But GR00T doesn’t know what “frisking” or “ultrasound guidance” means. That’s where task-specific training begins.
Layer 2: human demonstration (the bottleneck)
Teleoperation systems like FastUMI, Mobile ALOHA, and JoyLo allow human experts to demonstrate tasks while robots record every sensor stream.
The Surgie project uses HTC Vive trackers and webcam-based hand pose estimation to capture high-fidelity bimanual demonstrations. Custom grasping configurations let operators switch between holding a scalpel, a stethoscope, or an ultrasound probe.
Quality matters more than quantity. One well-annotated demonstration with synchronized multi-modal data is worth 100 noisy recordings. The Centific GAZE pipeline (Krishna et al., NeurIPS 2025) demonstrates how AI-assisted pre-annotation can achieve 28%-32% reduction in human review time while maintaining annotation quality.
Layer 3: simulation at scale (the multiplier)
Real demonstrations are expensive. Simulation is cheap, but the “reality gap” can be fatal. In NVIDIA Isaac Sim, Centific Physical AI Center of Excellence (PACE) can simulate 100,000+ episodes in a short time frame:
Thousands of synthetic body types
Varied lighting, textures, and physics parameters
Injected edge cases (concealed objects, prosthetics, uncooperative subjects)
Adversarial scenarios that would be impossible to collect in reality
Domain randomization prevents overfitting simulation artifacts. Cosmos Transfer bridges the visual gap with photorealistic rendering.
But simulation-trained policies typically see 15%-30% performance drops when deployed to real robots. Closing this gap requires systematic simulation-to-reality validation—measuring where failures occur and iterating until transfer works. Neural reconstruction tools like NVIDIA Omniverse NuRec (using 3DGUT) can compress environment capture from days of manual modeling to an afternoon of photography, converting real spaces into photorealistic Isaac Sim scenes. Organizations training robots to perform pick and place in real facilities, like warehouses, clinics, care homes, can reconstruct the actual environment rather than approximating it.
However, this creates a subtle but important training challenge: photorealistic geometry does not automatically capture the unpredictable contact physics of a slipping grasp, a rolling object, or an item that shifts under load. A simulation that looks real but behaves ideally will produce policies that fail precisely in the moment of recovery. Closing this gap requires deliberately injecting grasp failure and recovery scenarios into neurally-reconstructed environments, not just running successful demonstrations in realistic scenes.
Layer 4: world models (the anticipation engine)
Using world models like NVIDIA Cosmos-Predict, robots anticipate, not just react:
“This passenger’s posture suggests they'll shift left in 2 seconds”
“The fabric texture indicates possible concealed rigid object”
“Based on tremor patterns, this elderly patient may need extra support”
Cosmos-Reason1 provides chain-of-thought reasoning that creates audit trails, which is critical for security and medical applications where every decision may be reviewed.
This anticipation capability is especially important for seemingly “simple” tasks like pick and place. Recent NVIDIA research makes this concrete: DreamZero (Ye et al., 2026), a World Action Model trained on the AgiBot dataset, found that standard Vision-Language-Action models default to pick-and-place motions regardless of instruction. This finding suggests that they overfit to dominant training behaviors rather than reasoning about the task.
A robot that cannot reason what it is doing also cannot recover when something goes wrong in mid-execution. When a grasped object slips, rotates unexpectedly, or drops entirely, recovery is not a scripted fallback; it requires the robot to re-evaluate the world state, re-plan grasp geometry, and execute a corrective action in real time. World models like Cosmos-Predict and the DreamDojo framework (trained on 44k hours of human egocentric video) give robots the predictive foundation to detect grasp failure before it becomes a drop, and to anticipate corrective trajectories before contact is lost.
Layer 5: reinforcement learning (the safety net)
Imitation learning teaches standard task execution. Reinforcement learning teaches recovery and safety. This distinction matters most for tasks that appear deceptively simple. Pick and place is the canonical “solved” robot task, but DreamZero’s evaluations show that even state-of-the-art VLAs achieve near-zero performance on pick-and-place variants in unseen environments, precisely because they were trained predominantly on successful executions.
Real pick-and-place in production involves dropped objects, slipped grasps, items that roll or deform on contact, and partial occlusions mid-motion. Data collection pipelines must deliberately capture these failure modes: teleoperated recovery sequences after intentional drops, grasp reattempts from perturbed positions, and reactive replanning when contact is lost. Without this failure coverage, reinforcement learning has no signal to optimize from when the happy path breaks down. Centific’s internal operational process recommends training with:
10× sampling weight on edge cases and failures
Safety constraints baked into reward functions (force limits are hard constraints, not soft penalties)
Adversarial training where simulated humans actively test system robustness
The robot learns: “When contact force exceeds the threshold, release immediately. When uncertainty is high, request human assistance. Never guess on a safety-critical decision.”
The human-in-the-loop imperative
What separates research demonstrations from production systems is not dexterity or autonomy, but how responsibility is structured once a system operates around people. In high-stakes, human-contact environments, keeping humans in the loop is a deliberate design choice that shapes system architecture, training, and deployment.
In security screening, realistic near-term deployments rely on a clear division of labor. The robot performs routine, physically repetitive screening actions with consistent force and coverage, reducing fatigue and variability. A human officer observes every interaction in real time through camera and sensor feeds, actively supervising rather than passively monitoring. Any anomaly, including unexpected sensor readings, atypical passenger movement, or elevated model uncertainty, triggers immediate human takeover. All interactions are fully recorded, with synchronized multimodal sensor data retained to support auditability, training refinement, and post-incident review.
This structure reflects an operational reality: robots can deliver consistency and endurance, but ambiguity and context still require human judgment. The system is designed so uncertainty escalates to a person instead of being resolved autonomously.
In medical assistance, the control boundary is even more explicit. A physician is always present and remains responsible for procedural decisions. The robot functions as an extension of the clinician’s physical capabilities, providing steadier positioning, repeatable motion, or controlled force application, without substituting medical judgment. Force limits are hardcoded below established injury thresholds rather than learned dynamically, ensuring conservative behavior under all conditions. Emergency stop mechanisms are always accessible and prioritized in the control stack, not treated as secondary safeguards.
Across both domains, autonomy is intentionally constrained. The objective is not to remove humans from the loop, but to design systems where machine execution and human accountability are clearly separated, enforceable, and auditable.
Full autonomy is not a realistic goal for high-stakes human contact and framing it as such obscures the real work ahead. The opportunity lies in building collaborative systems where human oversight is explicit by design and scaled through infrastructure, not eliminated in pursuit of autonomy for its own sake.
The data infrastructure gap
The fundamental challenge in humanoid AI is data infrastructure, not algorithms. Building a humanoid robot is largely a hardware problem, and the industry is making visible progress on that front. Actuators are improving. Sensors are getting cheaper and more capable. Form factors are converging. What is far less mature is the infrastructure required to train those robots to operate reliably in the physical world, especially around people.
Training a humanoid does not mean collecting a few successful demonstrations in a lab. It requires global networks of data collection facilities equipped with calibrated sensors that behave consistently across locations and platforms. Vision, depth, force, torque, and tactile streams must be synchronized with sub–5 millisecond precision so that actions, contact, and perception can be meaningfully aligned. Small timing errors at this layer cascade into brittle behavior later.
The data itself must span real-world diversity. That means variation across environments, lighting conditions, body types, clothing, mobility patterns, and edge cases that rarely appear in controlled settings. Success cases alone are not sufficient. Failures, recoveries, hesitation, and handoffs matter just as much, particularly for contact-rich tasks where safety and judgment are intertwined.
At this scale, quality assurance becomes a system, not a manual review step. Human demonstrations must be validated, annotated, and audited with consistency. In mature pipelines, first-pass quality matters because downstream correction is expensive. Programs that achieve high first-submission pass rates are not just more efficient; they are more predictable and governable.
Governance infrastructure is inseparable from this process. Physical interaction data often includes personally identifiable information, sensitive imagery, and regulated contexts. PII detection, compliance flagging, and chain-of-custody tracking must be built into the pipeline from the start, not added later. Without that foundation, data cannot be reused, shared, or defended once systems move toward deployment.
The gap between what a demo requires and what production demands is substantial. A compelling demo can be built with a few hundred carefully staged demonstrations, collected over weeks in a lab, on a single robot embodiment, and optimized around success cases. A production system requires tens of thousands of demonstrations collected over years, spanning real-world diversity, transferred across embodiments, and stress-tested on edge cases and failures.
This infrastructure does not yet exist at the scale required for widespread deployment. Until it does, progress in humanoid AI will continue to look impressive on stage and fragile in practice.
What to ask next
When you evaluate humanoid systems for real-world use, the most revealing questions are not about walking or grasping.
Ask how many demonstrations exist for the specific task. Ask how edge cases are represented. Ask what happens when something goes wrong. Ask how human oversight is integrated.
The answers distinguish a demonstration from a deployment path.
The humanoid race is not about who builds the most robots. It is about who builds the data infrastructure to train robots for tasks that matter.
That race has only just begun.
Centific can help
Centific’s physical AI practice enables machines to perceive, reason, and act reliably in complex real-world environments. We combine computer vision, simulation, sensor fusion, and adaptive control across dynamic settings including warehouses, factories, and urban environments. We contribute purpose-built datasets and evaluation frameworks for physical and embodied AI development, including ego-centric video with synchronized IMU and depth data, manipulation task demonstrations with annotated intent and object state transitions, and sim-to-real transfer benchmarks that bridge structured simulation outputs to real-world domain adaptation pipelines.
Our annotation workflows are purpose-aligned to world foundation model architectures — supporting Nvidia Cosmos-style physics-aware video generation and Meta V-JEPA 2-style latent-space predictive training — with reasoning traces that go beyond labeling what happened to capturing why it happened and what should happen next. These capabilities are grounded in research-backed methodologies and strategic partnerships with NVIDIA and UC San Diego and several other universities, helping move physical AI from research prototype to scalable deployment alongside people in real-world settings with high-fidelity real-world data.
We support physical AI development through a global network of robotics data factories, distributed data collectors, and operating businesses that generate diverse training signals from real environments. These pipelines capture the observational and behavioral data needed to train and validate robots that must operate in unpredictable conditions outside the lab. Real-world data allows organizations to move beyond purely simulated environments and build physical AI systems that adapt, learn, and function reliably in the physical world.
References
Ye, S., et al. “DreamZero: World Action Models are Zero-shot Policies.” NVIDIA (2026). dreamzero0.github.io
Gao, S., Liang, W., et al. “DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos.” arXiv:2602.06949 (2026). dreamdojo-world.github.io
NVIDIA Developer Blog. “How to Instantly Render Real-World Scenes in Interactive Simulation.” Omniverse NuRec / 3DGUT (2025). developer.nvidia.com/blog/how-to-instantly-render-real-world-scenes-in-interactive-simulation
Yip, M. "The robot will see you now: Foundation models are the path forward for autonomous robotic surgery." Science Robotics (July 2025).
Krishna, L. "GAZE: Governance-Aware pre-annotation for Zero-shot World Model Environments." arXiv:2510.14992 (October 2025).
Atar, S., et al. "Humanoids in Hospitals: A Technical Study of Humanoid Surrogates for Dexterous Medical Interventions." arXiv:2503.12725 (2025). surgie-humanoid.github.io
Khazatsky, A., et al. "DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset." arXiv:2403.12945 (2024).
Brohan, A., et al. "RT-X: Open X-Embodiment Robotic Learning Datasets and RT-X Models." arXiv:2310.08864 (2023).
Li, C., et al. "BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation." CoRL (2024).
Dass, S., et al. "PATO: Policy Assisted TeleOperation for Scalable Robot Data Collection." arXiv:2212.04708 (2023).
Mandlekar, A., et al. "Scaling Robot Supervision to Hundreds of Hours with RoboTurk." RSS (2019).
Are your ready to get
modular
AI solutions delivered?
Connect data, models, and people — in one enterprise-ready platform.
Latest Insights



Connect with Centific
Updates from the frontier of AI data.
Receive updates on platform improvements, new workflows, evaluation capabilities, data quality enhancements, and best practices for enterprise AI teams.