" height="2.0768733066194303px" id="D9zvikPGQ" transform="translate(2.998 0.199)" width="5.731236321640176px"/><path d="M 0.187 0.574 L 3.457 3.297 C 3.457 3.297 3.662 3.483 3.885 3.483 C 4.089 3.483 4.312 3.297 4.312 3.297 L 7.582 0.574 C 7.713 0.481 7.768 0.313 7.675 0.163 C 7.601 0.014 7.415 -0.042 7.267 0.033 L 4.182 2.103 L 3.903 2.271 C 3.885 2.271 3.847 2.271 3.81 2.271 L 3.531 2.103 L 0.447 0.033 C 0.298 -0.042 0.131 0.033 0.038 0.163 C -0.036 0.313 0.001 0.481 0.131 0.574 Z" fill="rgb(0, 0, 0)" height="3.483465559558452px" id="XHPDa9C06" transform="translate(1.975 1.124)" width="7.7215397232611345px"/><path d="M 1.933 5.727 C 2.063 5.652 2.1 5.503 2.044 5.372 L 0.966 2.91 C 0.966 2.892 0.966 2.873 0.966 2.854 L 2.044 0.392 C 2.1 0.262 2.044 0.113 1.933 0.038 C 1.803 -0.037 1.654 0.001 1.58 0.131 L 0.112 2.519 C 0.112 2.519 0 2.705 0 2.873 C 0 3.078 0.112 3.246 0.112 3.246 L 1.58 5.634 C 1.654 5.745 1.803 5.783 1.933 5.727 Z" fill="rgb(0, 0, 0)" height="5.752520201428617px" id="fSIVTyYyB" transform="translate(9.688 3.208)" width="2.0692037208998664px"/><path d="M 2.899 0.187 L 0.186 3.47 C 0.186 3.47 0 3.675 0 3.899 C 0 4.104 0.186 4.328 0.186 4.328 L 2.899 7.611 C 2.992 7.741 3.159 7.797 3.308 7.704 C 3.456 7.629 3.512 7.443 3.438 7.294 L 1.375 4.197 L 1.208 3.918 C 1.208 3.899 1.208 3.862 1.208 3.824 L 1.375 3.545 L 3.438 0.448 C 3.512 0.299 3.438 0.131 3.308 0.038 C 3.159 -0.037 2.992 0.001 2.899 0.131 Z" fill="rgb(0, 0, 0)" height="7.750209501286653px" id="XEy5_M_wF" transform="translate(7.365 2.182)" width="3.470578512630766px"/><path d="M 0.026 1.94 C 0.1 2.07 0.249 2.108 0.379 2.052 L 2.832 0.97 C 2.85 0.97 2.869 0.97 2.887 0.97 L 5.34 2.052 C 5.47 2.108 5.619 2.052 5.693 1.94 C 5.768 1.809 5.731 1.66 5.6 1.585 L 3.222 0.112 C 3.222 0.112 3.036 0 2.869 0 C 2.664 0 2.497 0.112 2.497 0.112 L 0.119 1.585 C 0.007 1.66 -0.03 1.809 0.026 1.94 Z" fill="rgb(0, 0, 0)" height="2.0768899917602535px" id="GVAyPotmc" transform="translate(3.029 9.923)" width="5.731234655014601px"/><path d="M 7.535 2.91 L 4.264 0.187 C 4.264 0.187 4.06 0 3.837 0 C 3.633 0 3.41 0.187 3.41 0.187 L 0.139 2.91 C 0.009 3.003 -0.047 3.171 0.046 3.32 C 0.12 3.469 0.306 3.525 0.455 3.451 L 3.54 1.38 L 3.818 1.212 C 3.837 1.212 3.874 1.212 3.911 1.212 L 4.19 1.38 L 7.275 3.451 C 7.423 3.525 7.591 3.451 7.684 3.32 C 7.758 3.171 7.721 3.003 7.591 2.91 Z" fill="rgb(0, 0, 0)" height="3.483478327665332px" id="UJGiliWlr" transform="translate(2.06 7.592)" width="7.721540951544936px"/><path d="M 0.137 0.026 C 0.007 0.1 -0.031 0.25 0.025 0.38 L 1.103 2.842 C 1.103 2.861 1.103 2.879 1.103 2.898 L 0.025 5.36 C -0.031 5.491 0.025 5.64 0.137 5.715 C 0.267 5.789 0.415 5.752 0.49 5.621 L 1.958 3.234 C 1.958 3.234 2.069 3.047 2.069 2.879 C 2.069 2.674 1.958 2.506 1.958 2.506 L 0.49 0.119 C 0.415 0.007 0.267 -0.03 0.137 0.026 Z" fill="rgb(0, 0, 0)" height="5.752526692867306px" id="DM37PXgJd" transform="translate(0 3.239)" width="2.0691900389284807px"/><path d="M 0.572 7.6 L 3.285 4.318 C 3.285 4.318 3.471 4.112 3.471 3.889 C 3.471 3.683 3.285 3.46 3.285 3.46 L 0.572 0.14 C 0.479 0.009 0.312 -0.047 0.163 0.046 C 0.014 0.121 -0.042 0.307 0.033 0.457 L 2.095 3.553 L 2.263 3.833 C 2.263 3.851 2.263 3.889 2.263 3.926 L 2.095 4.206 L 0.033 7.302 C -0.042 7.451 0.033 7.619 0.163 7.712 C 0.312 7.787 0.479 7.749 0.572 7.619 Z" fill="rgb(0, 0, 0)" height="7.750215230634018px" id="omz1nxiI6" transform="translate(0.922 2.23)" width="3.470588058544221px"/><path d="M 4.007 1.424 C 4.508 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.787 2.29 5.927 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.787 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.863 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.927 5.725 C 5.62 6.591 4.981 7.01 3.979 7.01 C 2.977 7.01 2.755 6.758 2.337 6.256 C 1.92 5.753 1.725 5.083 1.725 4.189 C 1.725 3.295 1.92 2.625 2.337 2.15 C 2.755 1.648 3.283 1.424 3.979 1.424 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="fGIMtJKmR" transform="translate(15.609 3.128)" width="7.735096310284753px"/><path d="M 6.093 0.503 C 5.481 0.168 4.814 0 4.034 0 C 3.255 0 2.532 0.168 1.92 0.531 C 1.308 0.866 0.835 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.529 6.423 C 0.89 7.066 1.363 7.568 1.976 7.903 C 2.588 8.267 3.283 8.434 4.062 8.434 C 4.841 8.434 5.815 8.183 6.455 7.708 C 7.095 7.233 7.54 6.619 7.791 5.865 L 5.982 5.865 C 5.62 6.619 4.98 7.01 4.062 7.01 C 3.144 7.01 2.894 6.814 2.476 6.423 C 2.031 6.032 1.809 5.502 1.753 4.859 L 7.958 4.859 C 7.985 4.608 8.013 4.329 8.013 4.022 C 8.013 3.24 7.846 2.541 7.512 1.927 C 7.179 1.313 6.706 0.838 6.121 0.503 Z M 1.725 3.491 C 1.809 2.849 2.059 2.346 2.476 1.983 C 2.894 1.62 3.395 1.424 3.979 1.424 C 4.563 1.424 5.147 1.62 5.593 1.983 C 6.038 2.346 6.26 2.849 6.26 3.491 L 1.753 3.491 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="qaL5FVZij" transform="translate(24.013 3.128)" width="8.01332295195354px"/><path d="M 5.815 0.391 C 5.314 0.112 4.73 0 4.09 0 C 3.45 0 3.144 0.084 2.727 0.279 C 2.309 0.475 1.948 0.726 1.669 1.061 L 1.669 0.14 L 0 0.14 L 0 8.294 L 1.669 8.294 L 1.669 3.742 C 1.669 3.016 1.864 2.458 2.226 2.067 C 2.587 1.676 3.088 1.48 3.729 1.48 C 4.368 1.48 4.841 1.676 5.231 2.067 C 5.592 2.458 5.787 3.016 5.787 3.742 L 5.787 8.294 L 7.457 8.294 L 7.457 3.491 C 7.457 2.737 7.318 2.122 7.04 1.592 C 6.761 1.061 6.344 0.67 5.843 0.419 Z" fill="rgb(0, 0, 0)" height="8.294435702953454px" id="WDjXqIjZT" transform="translate(33.166 3.128)" width="7.4567073744807075px"/><path d="M 2.643 0 L 0.946 0 L 0.946 2.039 L 0 2.039 L 0 3.407 L 0.946 3.407 L 0.946 7.931 C 0.946 8.741 1.141 9.3 1.558 9.663 C 1.948 10.026 2.532 10.193 3.311 10.193 L 4.647 10.193 L 4.647 8.797 L 3.617 8.797 C 3.283 8.797 3.033 8.741 2.894 8.602 C 2.755 8.462 2.671 8.239 2.671 7.931 L 2.671 3.407 L 4.647 3.407 L 4.647 2.039 L 2.671 2.039 L 2.671 0 Z" fill="rgb(0, 0, 0)" height="10.193494685087567px" id="nZ8KAi6H2" transform="translate(41.458 1.229)" width="4.646524285330045px"/><path d="M 1.085 0 C 0.779 0 0.528 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.095 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(0, 0, 0)" height="2.1783368721996954px" id="xofK7bnqV" transform="translate(47.384 0)" width="2.1424521645366994px"/><path d="M 1.669 0 L 0 0 L 0 8.155 L 1.669 8.155 Z" fill="rgb(0, 0, 0)" height="8.154788300335934px" id="owXtEW3wx" transform="translate(47.607 3.267)" width="1.6694896185170123px"/><path d="M 1.085 0 C 0.779 0 0.529 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.067 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(0, 0, 0)" height="2.1783368721996954px" id="qYXTLcef6" transform="translate(55.842 0)" width="2.1424521645367136px"/><path d="M 4.007 7.01 C 3.311 7.01 2.783 6.758 2.365 6.256 C 1.948 5.753 1.753 5.083 1.753 4.189 C 1.753 3.295 1.948 2.625 2.365 2.15 C 2.783 1.648 3.311 1.424 4.007 1.424 C 4.702 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.788 2.29 5.926 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.788 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.862 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.926 5.725 C 5.621 6.591 4.981 7.01 3.979 7.01 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="YVPoMPmqZ" transform="translate(59.265 3.128)" width="7.735226155870485px"/><path d="M 6.872 3.268 L 2.643 3.268 L 2.643 2.681 C 2.643 2.206 2.754 1.871 2.949 1.676 C 3.144 1.508 3.478 1.396 3.923 1.396 L 3.923 0 C 2.921 0 2.17 0.223 1.697 0.642 C 1.196 1.061 0.946 1.759 0.946 2.681 L 0.946 3.268 L 0 3.268 L 0 4.636 L 0.946 4.636 L 0.946 11.422 L 2.643 11.422 L 2.643 4.636 L 5.203 4.636 L 5.203 11.422 L 6.872 11.422 Z" fill="rgb(0, 0, 0)" height="11.422308710362525px" id="mR0Sii5R7" transform="translate(50.863 0)" width="6.872402238697973px"/></g></svg>)
" width="11.757210121961878px"><path d="M 5.706 0.137 C 5.631 0.007 5.483 -0.031 5.353 0.025 L 2.9 1.107 C 2.881 1.107 2.862 1.107 2.844 1.107 L 0.391 0.025 C 0.261 -0.031 0.112 0.025 0.038 0.137 C -0.036 0.268 0.001 0.417 0.131 0.491 L 2.509 1.965 C 2.509 1.965 2.695 2.077 2.862 2.077 C 3.067 2.077 3.234 1.965 3.234 1.965 L 5.613 0.491 C 5.724 0.417 5.761 0.268 5.706 0.137 Z" fill="rgb(255, 255, 255)" height="2.0768733060957265px" id="JOqgQgeXH" transform="translate(2.998 0)" width="5.731236321640178px"/><path d="M 0.187 0.574 L 3.457 3.297 C 3.457 3.297 3.662 3.483 3.885 3.483 C 4.089 3.483 4.312 3.297 4.312 3.297 L 7.582 0.574 C 7.713 0.481 7.768 0.313 7.675 0.163 C 7.601 0.014 7.415 -0.042 7.267 0.033 L 4.182 2.103 L 3.903 2.271 C 3.885 2.271 3.847 2.271 3.81 2.271 L 3.531 2.103 L 0.447 0.033 C 0.298 -0.042 0.131 0.033 0.038 0.163 C -0.036 0.313 0.001 0.481 0.131 0.574 Z" fill="rgb(255, 255, 255)" height="3.483465570588767px" id="Zd5XdemVt" transform="translate(1.975 0.925)" width="7.721539723261137px"/><path d="M 1.933 5.727 C 2.063 5.652 2.1 5.503 2.044 5.372 L 0.966 2.91 C 0.966 2.892 0.966 2.873 0.966 2.854 L 2.044 0.392 C 2.1 0.262 2.044 0.113 1.933 0.038 C 1.803 -0.037 1.654 0.001 1.58 0.131 L 0.112 2.519 C 0.112 2.519 0 2.705 0 2.873 C 0 3.078 0.112 3.246 0.112 3.246 L 1.58 5.634 C 1.654 5.745 1.803 5.783 1.933 5.727 Z" fill="rgb(255, 255, 255)" height="5.752520201428616px" id="wm4QOyIBO" transform="translate(9.688 3.009)" width="2.069203720899866px"/><path d="M 2.899 0.187 L 0.186 3.47 C 0.186 3.47 0 3.675 0 3.899 C 0 4.104 0.186 4.328 0.186 4.328 L 2.899 7.611 C 2.992 7.741 3.159 7.797 3.308 7.704 C 3.456 7.629 3.512 7.443 3.438 7.294 L 1.375 4.197 L 1.208 3.918 C 1.208 3.899 1.208 3.862 1.208 3.824 L 1.375 3.545 L 3.438 0.448 C 3.512 0.299 3.438 0.131 3.308 0.038 C 3.159 -0.037 2.992 0.001 2.899 0.131 Z" fill="rgb(255, 255, 255)" height="7.750209542168115px" id="Tb0_95onW" transform="translate(7.365 1.983)" width="3.470578512630766px"/><path d="M 0.026 1.94 C 0.1 2.07 0.249 2.108 0.379 2.052 L 2.832 0.97 C 2.85 0.97 2.869 0.97 2.887 0.97 L 5.34 2.052 C 5.47 2.108 5.619 2.052 5.693 1.94 C 5.768 1.809 5.731 1.66 5.6 1.585 L 3.222 0.112 C 3.222 0.112 3.036 0 2.869 0 C 2.664 0 2.497 0.112 2.497 0.112 L 0.119 1.585 C 0.007 1.66 -0.03 1.809 0.026 1.94 Z" fill="rgb(255, 255, 255)" height="2.07689008196461px" id="mLkmMllwc" transform="translate(3.029 9.724)" width="5.731234655014603px"/><path d="M 7.535 2.91 L 4.264 0.187 C 4.264 0.187 4.06 0 3.837 0 C 3.633 0 3.41 0.187 3.41 0.187 L 0.139 2.91 C 0.009 3.003 -0.047 3.171 0.046 3.32 C 0.12 3.469 0.306 3.525 0.455 3.451 L 3.54 1.38 L 3.818 1.212 C 3.837 1.212 3.874 1.212 3.911 1.212 L 4.19 1.38 L 7.275 3.451 C 7.423 3.525 7.591 3.451 7.684 3.32 C 7.758 3.171 7.721 3.003 7.591 2.91 Z" fill="rgb(255, 255, 255)" height="3.483478327665331px" id="r0d9h4JTL" transform="translate(2.06 7.392)" width="7.7215409515449345px"/><path d="M 0.137 0.026 C 0.007 0.1 -0.031 0.25 0.025 0.38 L 1.103 2.842 C 1.103 2.861 1.103 2.879 1.103 2.898 L 0.025 5.36 C -0.031 5.491 0.025 5.64 0.137 5.715 C 0.267 5.789 0.415 5.752 0.49 5.621 L 1.958 3.234 C 1.958 3.234 2.069 3.047 2.069 2.879 C 2.069 2.674 1.958 2.506 1.958 2.506 L 0.49 0.119 C 0.415 0.007 0.267 -0.03 0.137 0.026 Z" fill="rgb(255, 255, 255)" height="5.752526692867306px" id="yi3WcGLKq" transform="translate(0 3.04)" width="2.0691900389284807px"/><path d="M 0.572 7.6 L 3.285 4.318 C 3.285 4.318 3.471 4.112 3.471 3.889 C 3.471 3.683 3.285 3.46 3.285 3.46 L 0.572 0.14 C 0.479 0.009 0.312 -0.047 0.163 0.046 C 0.014 0.121 -0.042 0.307 0.033 0.457 L 2.095 3.553 L 2.263 3.833 C 2.263 3.851 2.263 3.889 2.263 3.926 L 2.095 4.206 L 0.033 7.302 C -0.042 7.451 0.033 7.619 0.163 7.712 C 0.312 7.787 0.479 7.749 0.572 7.619 Z" fill="rgb(255, 255, 255)" height="7.750215283552243px" id="p6XslZnAU" transform="translate(0.922 2.031)" width="3.4705880585442213px"/></g><path d="M 4.007 1.424 C 4.508 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.787 2.29 5.927 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.787 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.863 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.927 5.725 C 5.62 6.591 4.981 7.01 3.979 7.01 C 2.977 7.01 2.755 6.758 2.337 6.256 C 1.92 5.753 1.725 5.083 1.725 4.189 C 1.725 3.295 1.92 2.625 2.337 2.15 C 2.755 1.648 3.283 1.424 3.979 1.424 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="d2DNCsqwq" transform="translate(15.609 3.128)" width="7.735096310284753px"/><path d="M 6.093 0.503 C 5.481 0.168 4.814 0 4.034 0 C 3.255 0 2.532 0.168 1.92 0.531 C 1.308 0.866 0.835 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.529 6.423 C 0.89 7.066 1.363 7.568 1.976 7.903 C 2.588 8.267 3.283 8.434 4.062 8.434 C 4.841 8.434 5.815 8.183 6.455 7.708 C 7.095 7.233 7.54 6.619 7.791 5.865 L 5.982 5.865 C 5.62 6.619 4.98 7.01 4.062 7.01 C 3.144 7.01 2.894 6.814 2.476 6.423 C 2.031 6.032 1.809 5.502 1.753 4.859 L 7.958 4.859 C 7.985 4.608 8.013 4.329 8.013 4.022 C 8.013 3.24 7.846 2.541 7.512 1.927 C 7.179 1.313 6.706 0.838 6.121 0.503 Z M 1.725 3.491 C 1.809 2.849 2.059 2.346 2.476 1.983 C 2.894 1.62 3.395 1.424 3.979 1.424 C 4.563 1.424 5.147 1.62 5.593 1.983 C 6.038 2.346 6.26 2.849 6.26 3.491 L 1.753 3.491 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="NZQSgmK3B" transform="translate(24.013 3.128)" width="8.01332295195354px"/><path d="M 5.815 0.391 C 5.314 0.112 4.73 0 4.09 0 C 3.45 0 3.144 0.084 2.727 0.279 C 2.309 0.475 1.948 0.726 1.669 1.061 L 1.669 0.14 L 0 0.14 L 0 8.294 L 1.669 8.294 L 1.669 3.742 C 1.669 3.016 1.864 2.458 2.226 2.067 C 2.587 1.676 3.088 1.48 3.729 1.48 C 4.368 1.48 4.841 1.676 5.231 2.067 C 5.592 2.458 5.787 3.016 5.787 3.742 L 5.787 8.294 L 7.457 8.294 L 7.457 3.491 C 7.457 2.737 7.318 2.122 7.04 1.592 C 6.761 1.061 6.344 0.67 5.843 0.419 Z" fill="rgb(255, 255, 255)" height="8.294435702953454px" id="y4C5qOSA0" transform="translate(33.166 3.128)" width="7.4567073744807075px"/><path d="M 2.643 0 L 0.946 0 L 0.946 2.039 L 0 2.039 L 0 3.407 L 0.946 3.407 L 0.946 7.931 C 0.946 8.741 1.141 9.3 1.558 9.663 C 1.948 10.026 2.532 10.193 3.311 10.193 L 4.647 10.193 L 4.647 8.797 L 3.617 8.797 C 3.283 8.797 3.033 8.741 2.894 8.602 C 2.755 8.462 2.671 8.239 2.671 7.931 L 2.671 3.407 L 4.647 3.407 L 4.647 2.039 L 2.671 2.039 L 2.671 0 Z" fill="rgb(255, 255, 255)" height="10.193494685087567px" id="HConpA1k2" transform="translate(41.458 1.229)" width="4.646524285330045px"/><path d="M 1.085 0 C 0.779 0 0.528 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.095 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(255, 255, 255)" height="2.1783368721996954px" id="EuoH5GVjb" transform="translate(47.384 0)" width="2.1424521645366994px"/><path d="M 1.669 0 L 0 0 L 0 8.155 L 1.669 8.155 Z" fill="rgb(255, 255, 255)" height="8.154788300335934px" id="zg308Vtf3" transform="translate(47.607 3.267)" width="1.6694896185170123px"/><path d="M 1.085 0 C 0.779 0 0.529 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.067 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(255, 255, 255)" height="2.1783368721996954px" id="SaMxhxR35" transform="translate(55.842 0)" width="2.1424521645367136px"/><path d="M 4.007 7.01 C 3.311 7.01 2.783 6.758 2.365 6.256 C 1.948 5.753 1.753 5.083 1.753 4.189 C 1.753 3.295 1.948 2.625 2.365 2.15 C 2.783 1.648 3.311 1.424 4.007 1.424 C 4.702 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.788 2.29 5.926 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.788 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.862 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.926 5.725 C 5.621 6.591 4.981 7.01 3.979 7.01 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="HetImuuV4" transform="translate(59.265 3.128)" width="7.735226155870485px"/><path d="M 6.872 3.268 L 2.643 3.268 L 2.643 2.681 C 2.643 2.206 2.754 1.871 2.949 1.676 C 3.144 1.508 3.478 1.396 3.923 1.396 L 3.923 0 C 2.921 0 2.17 0.223 1.697 0.642 C 1.196 1.061 0.946 1.759 0.946 2.681 L 0.946 3.268 L 0 3.268 L 0 4.636 L 0.946 4.636 L 0.946 11.422 L 2.643 11.422 L 2.643 4.636 L 5.203 4.636 L 5.203 11.422 L 6.872 11.422 Z" fill="rgb(255, 255, 255)" height="11.422308710362525px" id="Xc4NeSznw" transform="translate(50.863 0)" width="6.872402238697973px"/></g></svg>)


12 min read time
AI Summary by Centific
Turn this article into insights
with AI-powered summaries
Topics

Centific AI Research Team
Ashi Jain
Kriti Banka
Manish Mehta
Naman Khandelwal
Parth Kulshreshtha
Sunil Kothari
AI models often appear more capable than they truly are because their performance is judged against benchmarks that abstract away how software is built inside real organizations. When performance is measured on isolated puzzles instead of real repositories, workflows, and constraints, models can appear production-ready while struggling in enterprise environments. Correcting this gap requires grounding both evaluation and development in real code and retaining human expertise where judgment and context matter.
Evaluating models against real enterprise code surfaces a second, more practical challenge. Even when models are tested in realistic development environments, general-purpose LLMs consistently fall short on domain-specific generation. Financial algorithms, bioinformatics pipelines, robotics control systems, and other specialized workloads demand an understanding of domain rules, standards, and edge cases that generic models do not reliably possess.
Addressing this gap requires more than prompt tuning; it calls for disciplined data curation, human-in-the-loop validation, and fine-tuning workflows designed for enterprise conditions.
Why domain specialization is necessary
General-purpose LLMs are optimized for breadth. They perform well across many tasks. But that generality becomes a limitation when enterprises need code that reflects industry rules, regulatory constraints, and hard-won institutional knowledge. In practice, syntactically correct code is often insufficient. What matters is whether the code aligns with domain logic, internal standards, and production requirements.
This mirrors the problem described in our earlier benchmark analysis. Just as puzzle-based benchmarks misrepresent real development, generic models misrepresent what enterprise-ready code generation actually entails.
Overview of the fine-tuning workflow
The workflow presented here outlines a production-ready system for collecting, curating, fine-tuning, and evaluating LLMs on domain-specific codebases. It is designed around three principles that align directly with our earlier findings:
Real enterprise data must replace synthetic abstractions
Human judgment must guide ambiguity, not be removed from the process
Evaluation must reflect how code is actually written, reviewed, and deployed
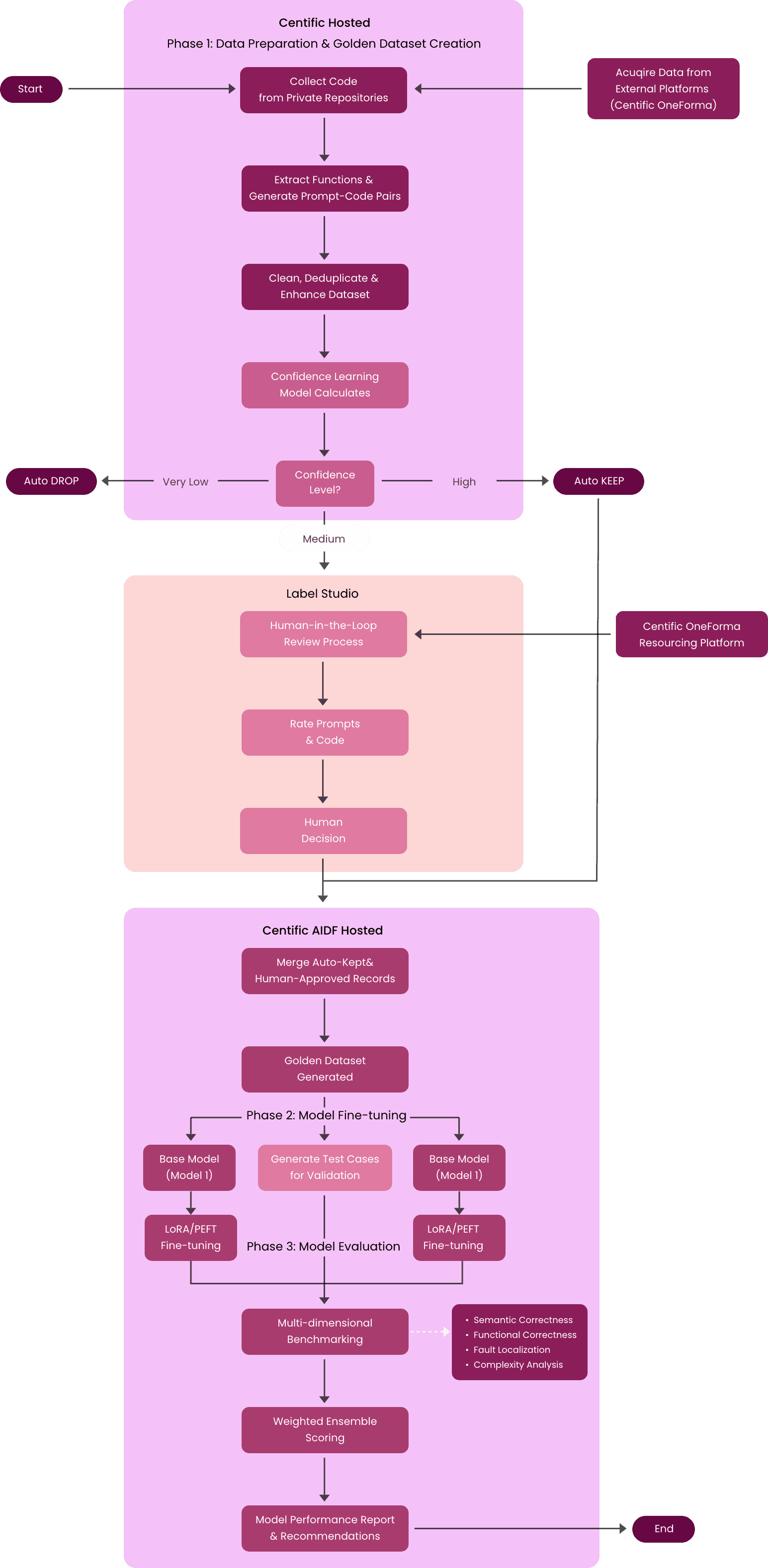
The figure above illustrates the core workflow for domain-specific code generation, focusing on data preparation, fine-tuning, and evaluation.
The three-phase fine-tuning architecture
Building domain-specific LLMs requires a workflow that mirrors how enterprise software is created, reviewed, and deployed. This architecture organizes that work into three connected phases, each addressing a distinct risk: poor data quality, shallow specialization, and misleading evaluation.
Phase 1: data preparation and golden dataset creation
The foundation of domain-specific performance is data that reflects real enterprise code, not synthetic examples. This phase focuses on assembling raw material from credible sources and shaping it into a dataset suitable for both training and evaluation.
Multi-source data collection
To capture the breadth and nuance of real-world development, data is drawn from multiple complementary sources rather than a single repository type.
Private repository mining: extract high-quality code from enterprise codebases with proper anonymization
External platform integration: rely on specialized data platforms (like Centific OneForma) for diverse code samples
Function extraction: parse repositories to identify and extract functions with their associated metadata
Prompt-code pair generation: create structured training examples linking natural language descriptions to code implementations
Raw collection alone is insufficient. Enterprise repositories contain noise, redundancy, and uneven quality that must be addressed before models ever see the data.
Quality control pipeline
This step introduces automated safeguards that narrow the dataset before any human effort is applied.
Data cleaning: automated deduplication, syntax validation, and noise removal processes
Dataset enhancement: standardize formatting, improve documentation, and enrich metadata
Confidence learning assessment: deploy machine learning models to score sample quality and difficulty
Three-tier quality classification
Very Low Confidence → Automatic rejection to eliminate poor-quality samples
High Confidence → Automatic inclusion for verified high-quality code
Medium Confidence → Human expert review through structured evaluation process
Automation reduces scale, but judgment is required where ambiguity remains. That is where human expertise becomes essential.
Human-in-the-Loop Validation
Human review is deliberately focused on the gray areas where automation cannot reliably determine quality or intent.
Expert review platform: integration with annotation tools (Label Studio) for systematic evaluation
Structured assessment: domain experts rate prompts for clarity and code for correctness
Quality scoring: comprehensive evaluation across multiple dimensions (functionality, readability, best practices)
Final decision gateway: human experts make keep, reject, or modify decisions for uncertain samples
Resource platform integration: scalable access to domain experts through specialized platforms
Once automated and human review converge, the remaining task is to assemble a dataset that is balanced, representative, and trusted.
Golden Dataset Assembly
This final step consolidates the output of earlier stages into a dataset suitable for enterprise-grade fine-tuning.
Merge validated samples: combine automatically approved and human-validated code samples
Distribution balancing: ensure representative coverage across different complexity levels and use cases
Final quality assurance: comprehensive review of the complete dataset before training begins
Phase 2: model fine-tuning
With a golden dataset in place, the focus shifts from data quality to controlled specialization. This phase injects domain knowledge into base models while preserving their general reasoning capabilities.
Parallel model training strategy
Training multiple variants in parallel allows teams to compare approaches rather than betting on a single configuration.
Multiple base models: train specialized variants simultaneously (Model 1, Model 2) to compare approaches
LoRA/PEFT implementation: parameter-efficient fine-tuning to maintain general capabilities while adding domain expertise
Test case generation: create comprehensive validation suites for each model variant during training
Training monitoring: real-time performance tracking and early stopping mechanisms
Fine-tuning alone does not guarantee readiness. Specialized models must still be evaluated against realistic criteria that reflect enterprise use.
Phase 3: model evaluation
Evaluation determines whether specialization translates into practical reliability. This phase moves beyond single metrics to assess performance across dimensions that matter in real development environments.
Multi-dimensional benchmarking
Each model is evaluated against multiple lenses to capture correctness, robustness, and maintainability.
Semantic correctness: evaluate whether generated code matches intended functionality and business logic
Functional correctness: test code execution, compilation success, and runtime behavior
Fault localization: systematic identification and categorization of error patterns
Complexity analysis: assessment using established metrics (Cyclomatic, Halstead, LOC)
Because no single metric captures enterprise readiness, results must be synthesized into a coherent signal.
Weighted ensemble scoring
Scores are combined in a way that reflects domain priorities rather than abstract benchmark conventions.
Composite metrics: combine multiple evaluation dimensions into unified quality scores
Domain-specific weighting: adjust metric importance based on business priorities and use case requirements
Performance comparison: direct benchmarking between model variants and baseline systems
The final step ensures that evaluation leads to actionable decisions, not just reports.
Final assessment
Results are translated into guidance that supports deployment and iteration.
Model performance report: comprehensive analysis of strengths, weaknesses, and deployment readiness
Recommendations: data-driven guidance for model selection and deployment strategies
Success criteria validation: confirmation that models meet predefined quality and performance thresholds
These outputs turn evaluation into a decision-making tool rather than a retrospective scorecard. They help teams determine not only which model performs best, but whether a model is ready to be trusted in real production environments.
Real-world use case: CodeCraft enterprise
To understand why domain-specific fine-tuning matters in practice, consider a hypothetical AI company, CodeCraft Enterprise, which offers a general-purpose code generation model to enterprise customers.
Despite strong benchmark performance, CodeCraft’s customers begin requesting capabilities that the model struggles to deliver reliably:
Financial services teams ask for Monte Carlo simulations that comply with internal risk models and regulatory constraints
Biotechnology teams need bioinformatics pipelines aligned with experimental protocols and lab-specific data formats
Manufacturing customers request PLC or robotics control logic with embedded safety interlocks
Aerospace teams require control algorithms compatible with proprietary simulation environments
In each case, the model produces syntactically correct code that fails under real conditions. The failures are not cosmetic. They stem from missing domain rules, incorrect assumptions about dependencies, and an inability to reason about context that never appears in public code.
CodeCraft’s leadership realizes that prompt engineering cannot close this gap. The problem is not how users ask for code; it is what the model has learned to recognize as “correct.”
Codecraft’s response
Rather than attempting to train a single model to cover every domain, CodeCraft adopts a specialization strategy:
Finance-focused models fine-tuned on quantitative libraries and internal risk patterns
Life-sciences models trained on validated pipelines and experimental workflows
Industrial models optimized for control systems, safety constraints, and embedded environments
Each model is trained using curated private repositories, filtered through quality gates, deduplicated, and reviewed by domain experts before fine-tuning.
Business impact for CodeCraft
As a result:
CodeCraft introduces premium API tiers priced above the general model
Enterprise contracts expand due to increased trust and lower failure rates
The company shifts from “general coding assistant” positioning to “domain-ready engineering systems”
As this example illustrates, domain specialization is not a marginal improvement, but a structural requirement for enterprise-grade code generation.
Technical deep dive: key workflow components
The fine-tuning workflow relies on a set of tightly integrated systems that manage data quality, validation, and evaluation at scale. Each component addresses a specific failure mode that emerges when models are trained on real enterprise code rather than synthetic or public datasets.
1. Confidence learning system
Large enterprise codebases contain wide variability in quality, completeness, and suitability for training. Rather than relying on binary inclusion rules, the workflow uses confidence learning to estimate how trustworthy each code sample is before it enters the training or evaluation pipeline.
The workflow employs a sophisticated confidence estimation approach:
Ensemble predictions: multiple models evaluate each code sample independently
Variance calculation: measure disagreement between model predictions
Entropy analysis: quantify uncertainty in prediction distribution
Confidence scoring: combine variance and entropy into unified confidence metric
Threshold-based categorization:
Below 0.3: auto-drop (low quality)
0.3-0.7: human review required (uncertain)
Above 0.7: auto-keep (high confidence)
Quality control: systematic filtering based on statistical confidence measures
This system allows automation to handle the majority of obvious cases while reserving human expertise for ambiguous or high-risk samples, keeping both quality and scalability in balance.
2. Test generation and validation
Even high-quality code samples provide limited value if their behavior cannot be validated. Because enterprise repositories often lack runnable or complete test suites, the workflow treats test discovery and generation as a first-class capability rather than an optional enhancement.
Automated test generation ensures functional correctness:
Function analysis: extract function signatures and analyze dependencies
Test category generation:
Unit tests: basic functionality validation for individual functions
Edge cases: boundary conditions, null inputs, extreme values
Integration tests: cross-module compatibility and data flow validation
Performance tests: execution time and resource usage benchmarks
Metadata integration: use function documentation for context-aware test creation
Comprehensive coverage: ensure all code paths and scenarios are tested
Automated validation: execute tests to verify code correctness before deployment
The workflow reduces false confidence and surfaces failures that only appear under realistic execution conditions by grounding validation in executable tests rather than static heuristics alone.
3. Multi-metric evaluation system
No single metric can capture whether a domain-specialized model is genuinely improving. The workflow therefore applies a layered evaluation strategy that measures behavior before and after fine-tuning, across correctness, quality, and real-world usability.
The workflow incorporates multiple evaluation approaches across two critical phases:
Pre-fine-tuning benchmarking (baseline establishment)
Before any specialization occurs, teams need a clear picture of how a general-purpose model behaves when confronted with real, domain-specific code. This baseline establishes the reference point against which all subsequent improvements are measured, and it helps distinguish genuine domain gaps from broader model limitations.
Domain-specific metrics: establish baseline performance on target domain tasks
Code quality assessment: measure compilation success rates, syntax correctness, and style compliance
Functional correctness: test execution success on domain-specific problem sets
Semantic understanding: evaluate code logic alignment with problem requirements
Performance profiling: benchmark inference speed, memory usage, and resource efficiency
Comparative analysis: compare against existing domain-specific tools and general-purpose models
Edge case handling: document baseline performance on boundary conditions and error scenarios
Grounding evaluation in this baseline helps teams avoid guessing where fine-tuning is needed. They can focus effort on the specific failure modes that matter most within their domain and operating constraints.
Post-fine-tuning evaluation (improvement measurement)
After fine-tuning, evaluation shifts to verifying how the model’s behavior has changed under the same conditions used to establish the baseline. This phase examines whether specialization improves domain performance while preserving reliability across adjacent tasks.
Performance Comparison: direct comparison with pre-training baseline metrics
Domain Improvement Analysis: quantify enhancement in specialized knowledge areas
Quality Metrics: measure improvements in code correctness, compilation success, and best practices adherence
Regression Testing: ensure general capabilities haven't degraded during specialization
A/B testing framework: compare fine-tuned model against baseline on real-world tasks
User satisfaction scoring: collect feedback from domain experts on code quality and usefulness
Deployment readiness assessment: validate model meets production performance standards
Results from this phase inform whether a model is suitable for production use, requires additional iteration, or should remain constrained to limited internal workflows.
Shared benchmarking methodologies across evaluation phases
The evaluation signals used before and after fine-tuning are generated through a common set of benchmarking methods. These methods provide consistency across both phases, allowing changes in model behavior to be attributed to fine-tuning rather than shifts in measurement criteria.
Functional correctness: tests execute successfully with expected outputs
Semantic correctness: code logic matches intended behavior and domain conventions
Taxonomy-guided fault localization: systematic error categorization and pattern analysis
Complexity analysis: evaluation using Cyclomatic complexity, Halstead metrics, and Lines of Code measures
Domain compliance: Adherence to industry standards, security practices, and regulatory requirements
Weighted ensemble scoring: Combined metrics weighted by complexity measures for holistic evaluation
These benchmarking methods remain constant across both evaluation phases, which keeps measurement stable while allowing model behavior to change. Consistent signals make it possible to observe real improvements, surface regressions early, and understand tradeoffs between correctness, complexity, and domain compliance without distorting results through shifting criteria.
From general capability to enterprise readiness
This fine-tuning workflow marks a move away from general-purpose code generation toward systems built for enterprise realities. Systematic collection, curation, and fine-tuning on domain-specific code allow LLM providers to:
Command premium pricing: specialized expertise supports 3–5x higher rates
Build deeper moats: domain knowledge creates durable competitive advantage
Enable new use cases: specialized models support applications out of reach for general systems
Establish enterprise trust: rigorous validation increases confidence in mission-critical environments
Organizations that adopt this approach early position themselves to lead in high-value enterprise segments, while reliance on undifferentiated, general-purpose models increases the risk of commoditization. For foundational LLM providers, sustained differentiation will depend on pairing broad model capabilities with domain-specific depth, supported by workflows that reflect how software is actually built and maintained.
How Centific helps
Centific helps organizations operationalize this transition through its AI Data Foundry, a foundation designed to work directly with private repositories, human expertise, and enterprise governance requirements. The platform supports golden dataset creation, domain-aware fine-tuning, and evaluation workflows that mirror real development conditions rather than synthetic benchmarks.
As a result, enterprises gain earlier insight into where models hold up, where guardrails are required, and where AI assistance can be applied safely to high-value systems without introducing hidden risk.
Are your ready to get
modular
AI solutions delivered?
Connect data, models, and people — in one enterprise-ready platform.
Latest Insights



Connect with Centific
Updates from the frontier of AI data.
Receive updates on platform improvements, new workflows, evaluation capabilities, data quality enhancements, and best practices for enterprise AI teams.