" height="2.0768733066194303px" id="D9zvikPGQ" transform="translate(2.998 0.199)" width="5.731236321640176px"/><path d="M 0.187 0.574 L 3.457 3.297 C 3.457 3.297 3.662 3.483 3.885 3.483 C 4.089 3.483 4.312 3.297 4.312 3.297 L 7.582 0.574 C 7.713 0.481 7.768 0.313 7.675 0.163 C 7.601 0.014 7.415 -0.042 7.267 0.033 L 4.182 2.103 L 3.903 2.271 C 3.885 2.271 3.847 2.271 3.81 2.271 L 3.531 2.103 L 0.447 0.033 C 0.298 -0.042 0.131 0.033 0.038 0.163 C -0.036 0.313 0.001 0.481 0.131 0.574 Z" fill="rgb(0, 0, 0)" height="3.483465559558452px" id="XHPDa9C06" transform="translate(1.975 1.124)" width="7.7215397232611345px"/><path d="M 1.933 5.727 C 2.063 5.652 2.1 5.503 2.044 5.372 L 0.966 2.91 C 0.966 2.892 0.966 2.873 0.966 2.854 L 2.044 0.392 C 2.1 0.262 2.044 0.113 1.933 0.038 C 1.803 -0.037 1.654 0.001 1.58 0.131 L 0.112 2.519 C 0.112 2.519 0 2.705 0 2.873 C 0 3.078 0.112 3.246 0.112 3.246 L 1.58 5.634 C 1.654 5.745 1.803 5.783 1.933 5.727 Z" fill="rgb(0, 0, 0)" height="5.752520201428617px" id="fSIVTyYyB" transform="translate(9.688 3.208)" width="2.0692037208998664px"/><path d="M 2.899 0.187 L 0.186 3.47 C 0.186 3.47 0 3.675 0 3.899 C 0 4.104 0.186 4.328 0.186 4.328 L 2.899 7.611 C 2.992 7.741 3.159 7.797 3.308 7.704 C 3.456 7.629 3.512 7.443 3.438 7.294 L 1.375 4.197 L 1.208 3.918 C 1.208 3.899 1.208 3.862 1.208 3.824 L 1.375 3.545 L 3.438 0.448 C 3.512 0.299 3.438 0.131 3.308 0.038 C 3.159 -0.037 2.992 0.001 2.899 0.131 Z" fill="rgb(0, 0, 0)" height="7.750209501286653px" id="XEy5_M_wF" transform="translate(7.365 2.182)" width="3.470578512630766px"/><path d="M 0.026 1.94 C 0.1 2.07 0.249 2.108 0.379 2.052 L 2.832 0.97 C 2.85 0.97 2.869 0.97 2.887 0.97 L 5.34 2.052 C 5.47 2.108 5.619 2.052 5.693 1.94 C 5.768 1.809 5.731 1.66 5.6 1.585 L 3.222 0.112 C 3.222 0.112 3.036 0 2.869 0 C 2.664 0 2.497 0.112 2.497 0.112 L 0.119 1.585 C 0.007 1.66 -0.03 1.809 0.026 1.94 Z" fill="rgb(0, 0, 0)" height="2.0768899917602535px" id="GVAyPotmc" transform="translate(3.029 9.923)" width="5.731234655014601px"/><path d="M 7.535 2.91 L 4.264 0.187 C 4.264 0.187 4.06 0 3.837 0 C 3.633 0 3.41 0.187 3.41 0.187 L 0.139 2.91 C 0.009 3.003 -0.047 3.171 0.046 3.32 C 0.12 3.469 0.306 3.525 0.455 3.451 L 3.54 1.38 L 3.818 1.212 C 3.837 1.212 3.874 1.212 3.911 1.212 L 4.19 1.38 L 7.275 3.451 C 7.423 3.525 7.591 3.451 7.684 3.32 C 7.758 3.171 7.721 3.003 7.591 2.91 Z" fill="rgb(0, 0, 0)" height="3.483478327665332px" id="UJGiliWlr" transform="translate(2.06 7.592)" width="7.721540951544936px"/><path d="M 0.137 0.026 C 0.007 0.1 -0.031 0.25 0.025 0.38 L 1.103 2.842 C 1.103 2.861 1.103 2.879 1.103 2.898 L 0.025 5.36 C -0.031 5.491 0.025 5.64 0.137 5.715 C 0.267 5.789 0.415 5.752 0.49 5.621 L 1.958 3.234 C 1.958 3.234 2.069 3.047 2.069 2.879 C 2.069 2.674 1.958 2.506 1.958 2.506 L 0.49 0.119 C 0.415 0.007 0.267 -0.03 0.137 0.026 Z" fill="rgb(0, 0, 0)" height="5.752526692867306px" id="DM37PXgJd" transform="translate(0 3.239)" width="2.0691900389284807px"/><path d="M 0.572 7.6 L 3.285 4.318 C 3.285 4.318 3.471 4.112 3.471 3.889 C 3.471 3.683 3.285 3.46 3.285 3.46 L 0.572 0.14 C 0.479 0.009 0.312 -0.047 0.163 0.046 C 0.014 0.121 -0.042 0.307 0.033 0.457 L 2.095 3.553 L 2.263 3.833 C 2.263 3.851 2.263 3.889 2.263 3.926 L 2.095 4.206 L 0.033 7.302 C -0.042 7.451 0.033 7.619 0.163 7.712 C 0.312 7.787 0.479 7.749 0.572 7.619 Z" fill="rgb(0, 0, 0)" height="7.750215230634018px" id="omz1nxiI6" transform="translate(0.922 2.23)" width="3.470588058544221px"/><path d="M 4.007 1.424 C 4.508 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.787 2.29 5.927 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.787 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.863 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.927 5.725 C 5.62 6.591 4.981 7.01 3.979 7.01 C 2.977 7.01 2.755 6.758 2.337 6.256 C 1.92 5.753 1.725 5.083 1.725 4.189 C 1.725 3.295 1.92 2.625 2.337 2.15 C 2.755 1.648 3.283 1.424 3.979 1.424 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="fGIMtJKmR" transform="translate(15.609 3.128)" width="7.735096310284753px"/><path d="M 6.093 0.503 C 5.481 0.168 4.814 0 4.034 0 C 3.255 0 2.532 0.168 1.92 0.531 C 1.308 0.866 0.835 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.529 6.423 C 0.89 7.066 1.363 7.568 1.976 7.903 C 2.588 8.267 3.283 8.434 4.062 8.434 C 4.841 8.434 5.815 8.183 6.455 7.708 C 7.095 7.233 7.54 6.619 7.791 5.865 L 5.982 5.865 C 5.62 6.619 4.98 7.01 4.062 7.01 C 3.144 7.01 2.894 6.814 2.476 6.423 C 2.031 6.032 1.809 5.502 1.753 4.859 L 7.958 4.859 C 7.985 4.608 8.013 4.329 8.013 4.022 C 8.013 3.24 7.846 2.541 7.512 1.927 C 7.179 1.313 6.706 0.838 6.121 0.503 Z M 1.725 3.491 C 1.809 2.849 2.059 2.346 2.476 1.983 C 2.894 1.62 3.395 1.424 3.979 1.424 C 4.563 1.424 5.147 1.62 5.593 1.983 C 6.038 2.346 6.26 2.849 6.26 3.491 L 1.753 3.491 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="qaL5FVZij" transform="translate(24.013 3.128)" width="8.01332295195354px"/><path d="M 5.815 0.391 C 5.314 0.112 4.73 0 4.09 0 C 3.45 0 3.144 0.084 2.727 0.279 C 2.309 0.475 1.948 0.726 1.669 1.061 L 1.669 0.14 L 0 0.14 L 0 8.294 L 1.669 8.294 L 1.669 3.742 C 1.669 3.016 1.864 2.458 2.226 2.067 C 2.587 1.676 3.088 1.48 3.729 1.48 C 4.368 1.48 4.841 1.676 5.231 2.067 C 5.592 2.458 5.787 3.016 5.787 3.742 L 5.787 8.294 L 7.457 8.294 L 7.457 3.491 C 7.457 2.737 7.318 2.122 7.04 1.592 C 6.761 1.061 6.344 0.67 5.843 0.419 Z" fill="rgb(0, 0, 0)" height="8.294435702953454px" id="WDjXqIjZT" transform="translate(33.166 3.128)" width="7.4567073744807075px"/><path d="M 2.643 0 L 0.946 0 L 0.946 2.039 L 0 2.039 L 0 3.407 L 0.946 3.407 L 0.946 7.931 C 0.946 8.741 1.141 9.3 1.558 9.663 C 1.948 10.026 2.532 10.193 3.311 10.193 L 4.647 10.193 L 4.647 8.797 L 3.617 8.797 C 3.283 8.797 3.033 8.741 2.894 8.602 C 2.755 8.462 2.671 8.239 2.671 7.931 L 2.671 3.407 L 4.647 3.407 L 4.647 2.039 L 2.671 2.039 L 2.671 0 Z" fill="rgb(0, 0, 0)" height="10.193494685087567px" id="nZ8KAi6H2" transform="translate(41.458 1.229)" width="4.646524285330045px"/><path d="M 1.085 0 C 0.779 0 0.528 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.095 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(0, 0, 0)" height="2.1783368721996954px" id="xofK7bnqV" transform="translate(47.384 0)" width="2.1424521645366994px"/><path d="M 1.669 0 L 0 0 L 0 8.155 L 1.669 8.155 Z" fill="rgb(0, 0, 0)" height="8.154788300335934px" id="owXtEW3wx" transform="translate(47.607 3.267)" width="1.6694896185170123px"/><path d="M 1.085 0 C 0.779 0 0.529 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.067 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(0, 0, 0)" height="2.1783368721996954px" id="qYXTLcef6" transform="translate(55.842 0)" width="2.1424521645367136px"/><path d="M 4.007 7.01 C 3.311 7.01 2.783 6.758 2.365 6.256 C 1.948 5.753 1.753 5.083 1.753 4.189 C 1.753 3.295 1.948 2.625 2.365 2.15 C 2.783 1.648 3.311 1.424 4.007 1.424 C 4.702 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.788 2.29 5.926 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.788 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.862 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.926 5.725 C 5.621 6.591 4.981 7.01 3.979 7.01 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="YVPoMPmqZ" transform="translate(59.265 3.128)" width="7.735226155870485px"/><path d="M 6.872 3.268 L 2.643 3.268 L 2.643 2.681 C 2.643 2.206 2.754 1.871 2.949 1.676 C 3.144 1.508 3.478 1.396 3.923 1.396 L 3.923 0 C 2.921 0 2.17 0.223 1.697 0.642 C 1.196 1.061 0.946 1.759 0.946 2.681 L 0.946 3.268 L 0 3.268 L 0 4.636 L 0.946 4.636 L 0.946 11.422 L 2.643 11.422 L 2.643 4.636 L 5.203 4.636 L 5.203 11.422 L 6.872 11.422 Z" fill="rgb(0, 0, 0)" height="11.422308710362525px" id="mR0Sii5R7" transform="translate(50.863 0)" width="6.872402238697973px"/></g></svg>)
" width="11.757210121961878px"><path d="M 5.706 0.137 C 5.631 0.007 5.483 -0.031 5.353 0.025 L 2.9 1.107 C 2.881 1.107 2.862 1.107 2.844 1.107 L 0.391 0.025 C 0.261 -0.031 0.112 0.025 0.038 0.137 C -0.036 0.268 0.001 0.417 0.131 0.491 L 2.509 1.965 C 2.509 1.965 2.695 2.077 2.862 2.077 C 3.067 2.077 3.234 1.965 3.234 1.965 L 5.613 0.491 C 5.724 0.417 5.761 0.268 5.706 0.137 Z" fill="rgb(255, 255, 255)" height="2.0768733060957265px" id="JOqgQgeXH" transform="translate(2.998 0)" width="5.731236321640178px"/><path d="M 0.187 0.574 L 3.457 3.297 C 3.457 3.297 3.662 3.483 3.885 3.483 C 4.089 3.483 4.312 3.297 4.312 3.297 L 7.582 0.574 C 7.713 0.481 7.768 0.313 7.675 0.163 C 7.601 0.014 7.415 -0.042 7.267 0.033 L 4.182 2.103 L 3.903 2.271 C 3.885 2.271 3.847 2.271 3.81 2.271 L 3.531 2.103 L 0.447 0.033 C 0.298 -0.042 0.131 0.033 0.038 0.163 C -0.036 0.313 0.001 0.481 0.131 0.574 Z" fill="rgb(255, 255, 255)" height="3.483465570588767px" id="Zd5XdemVt" transform="translate(1.975 0.925)" width="7.721539723261137px"/><path d="M 1.933 5.727 C 2.063 5.652 2.1 5.503 2.044 5.372 L 0.966 2.91 C 0.966 2.892 0.966 2.873 0.966 2.854 L 2.044 0.392 C 2.1 0.262 2.044 0.113 1.933 0.038 C 1.803 -0.037 1.654 0.001 1.58 0.131 L 0.112 2.519 C 0.112 2.519 0 2.705 0 2.873 C 0 3.078 0.112 3.246 0.112 3.246 L 1.58 5.634 C 1.654 5.745 1.803 5.783 1.933 5.727 Z" fill="rgb(255, 255, 255)" height="5.752520201428616px" id="wm4QOyIBO" transform="translate(9.688 3.009)" width="2.069203720899866px"/><path d="M 2.899 0.187 L 0.186 3.47 C 0.186 3.47 0 3.675 0 3.899 C 0 4.104 0.186 4.328 0.186 4.328 L 2.899 7.611 C 2.992 7.741 3.159 7.797 3.308 7.704 C 3.456 7.629 3.512 7.443 3.438 7.294 L 1.375 4.197 L 1.208 3.918 C 1.208 3.899 1.208 3.862 1.208 3.824 L 1.375 3.545 L 3.438 0.448 C 3.512 0.299 3.438 0.131 3.308 0.038 C 3.159 -0.037 2.992 0.001 2.899 0.131 Z" fill="rgb(255, 255, 255)" height="7.750209542168115px" id="Tb0_95onW" transform="translate(7.365 1.983)" width="3.470578512630766px"/><path d="M 0.026 1.94 C 0.1 2.07 0.249 2.108 0.379 2.052 L 2.832 0.97 C 2.85 0.97 2.869 0.97 2.887 0.97 L 5.34 2.052 C 5.47 2.108 5.619 2.052 5.693 1.94 C 5.768 1.809 5.731 1.66 5.6 1.585 L 3.222 0.112 C 3.222 0.112 3.036 0 2.869 0 C 2.664 0 2.497 0.112 2.497 0.112 L 0.119 1.585 C 0.007 1.66 -0.03 1.809 0.026 1.94 Z" fill="rgb(255, 255, 255)" height="2.07689008196461px" id="mLkmMllwc" transform="translate(3.029 9.724)" width="5.731234655014603px"/><path d="M 7.535 2.91 L 4.264 0.187 C 4.264 0.187 4.06 0 3.837 0 C 3.633 0 3.41 0.187 3.41 0.187 L 0.139 2.91 C 0.009 3.003 -0.047 3.171 0.046 3.32 C 0.12 3.469 0.306 3.525 0.455 3.451 L 3.54 1.38 L 3.818 1.212 C 3.837 1.212 3.874 1.212 3.911 1.212 L 4.19 1.38 L 7.275 3.451 C 7.423 3.525 7.591 3.451 7.684 3.32 C 7.758 3.171 7.721 3.003 7.591 2.91 Z" fill="rgb(255, 255, 255)" height="3.483478327665331px" id="r0d9h4JTL" transform="translate(2.06 7.392)" width="7.7215409515449345px"/><path d="M 0.137 0.026 C 0.007 0.1 -0.031 0.25 0.025 0.38 L 1.103 2.842 C 1.103 2.861 1.103 2.879 1.103 2.898 L 0.025 5.36 C -0.031 5.491 0.025 5.64 0.137 5.715 C 0.267 5.789 0.415 5.752 0.49 5.621 L 1.958 3.234 C 1.958 3.234 2.069 3.047 2.069 2.879 C 2.069 2.674 1.958 2.506 1.958 2.506 L 0.49 0.119 C 0.415 0.007 0.267 -0.03 0.137 0.026 Z" fill="rgb(255, 255, 255)" height="5.752526692867306px" id="yi3WcGLKq" transform="translate(0 3.04)" width="2.0691900389284807px"/><path d="M 0.572 7.6 L 3.285 4.318 C 3.285 4.318 3.471 4.112 3.471 3.889 C 3.471 3.683 3.285 3.46 3.285 3.46 L 0.572 0.14 C 0.479 0.009 0.312 -0.047 0.163 0.046 C 0.014 0.121 -0.042 0.307 0.033 0.457 L 2.095 3.553 L 2.263 3.833 C 2.263 3.851 2.263 3.889 2.263 3.926 L 2.095 4.206 L 0.033 7.302 C -0.042 7.451 0.033 7.619 0.163 7.712 C 0.312 7.787 0.479 7.749 0.572 7.619 Z" fill="rgb(255, 255, 255)" height="7.750215283552243px" id="p6XslZnAU" transform="translate(0.922 2.031)" width="3.4705880585442213px"/></g><path d="M 4.007 1.424 C 4.508 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.787 2.29 5.927 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.787 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.863 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.927 5.725 C 5.62 6.591 4.981 7.01 3.979 7.01 C 2.977 7.01 2.755 6.758 2.337 6.256 C 1.92 5.753 1.725 5.083 1.725 4.189 C 1.725 3.295 1.92 2.625 2.337 2.15 C 2.755 1.648 3.283 1.424 3.979 1.424 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="d2DNCsqwq" transform="translate(15.609 3.128)" width="7.735096310284753px"/><path d="M 6.093 0.503 C 5.481 0.168 4.814 0 4.034 0 C 3.255 0 2.532 0.168 1.92 0.531 C 1.308 0.866 0.835 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.529 6.423 C 0.89 7.066 1.363 7.568 1.976 7.903 C 2.588 8.267 3.283 8.434 4.062 8.434 C 4.841 8.434 5.815 8.183 6.455 7.708 C 7.095 7.233 7.54 6.619 7.791 5.865 L 5.982 5.865 C 5.62 6.619 4.98 7.01 4.062 7.01 C 3.144 7.01 2.894 6.814 2.476 6.423 C 2.031 6.032 1.809 5.502 1.753 4.859 L 7.958 4.859 C 7.985 4.608 8.013 4.329 8.013 4.022 C 8.013 3.24 7.846 2.541 7.512 1.927 C 7.179 1.313 6.706 0.838 6.121 0.503 Z M 1.725 3.491 C 1.809 2.849 2.059 2.346 2.476 1.983 C 2.894 1.62 3.395 1.424 3.979 1.424 C 4.563 1.424 5.147 1.62 5.593 1.983 C 6.038 2.346 6.26 2.849 6.26 3.491 L 1.753 3.491 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="NZQSgmK3B" transform="translate(24.013 3.128)" width="8.01332295195354px"/><path d="M 5.815 0.391 C 5.314 0.112 4.73 0 4.09 0 C 3.45 0 3.144 0.084 2.727 0.279 C 2.309 0.475 1.948 0.726 1.669 1.061 L 1.669 0.14 L 0 0.14 L 0 8.294 L 1.669 8.294 L 1.669 3.742 C 1.669 3.016 1.864 2.458 2.226 2.067 C 2.587 1.676 3.088 1.48 3.729 1.48 C 4.368 1.48 4.841 1.676 5.231 2.067 C 5.592 2.458 5.787 3.016 5.787 3.742 L 5.787 8.294 L 7.457 8.294 L 7.457 3.491 C 7.457 2.737 7.318 2.122 7.04 1.592 C 6.761 1.061 6.344 0.67 5.843 0.419 Z" fill="rgb(255, 255, 255)" height="8.294435702953454px" id="y4C5qOSA0" transform="translate(33.166 3.128)" width="7.4567073744807075px"/><path d="M 2.643 0 L 0.946 0 L 0.946 2.039 L 0 2.039 L 0 3.407 L 0.946 3.407 L 0.946 7.931 C 0.946 8.741 1.141 9.3 1.558 9.663 C 1.948 10.026 2.532 10.193 3.311 10.193 L 4.647 10.193 L 4.647 8.797 L 3.617 8.797 C 3.283 8.797 3.033 8.741 2.894 8.602 C 2.755 8.462 2.671 8.239 2.671 7.931 L 2.671 3.407 L 4.647 3.407 L 4.647 2.039 L 2.671 2.039 L 2.671 0 Z" fill="rgb(255, 255, 255)" height="10.193494685087567px" id="HConpA1k2" transform="translate(41.458 1.229)" width="4.646524285330045px"/><path d="M 1.085 0 C 0.779 0 0.528 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.095 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(255, 255, 255)" height="2.1783368721996954px" id="EuoH5GVjb" transform="translate(47.384 0)" width="2.1424521645366994px"/><path d="M 1.669 0 L 0 0 L 0 8.155 L 1.669 8.155 Z" fill="rgb(255, 255, 255)" height="8.154788300335934px" id="zg308Vtf3" transform="translate(47.607 3.267)" width="1.6694896185170123px"/><path d="M 1.085 0 C 0.779 0 0.529 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.067 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(255, 255, 255)" height="2.1783368721996954px" id="SaMxhxR35" transform="translate(55.842 0)" width="2.1424521645367136px"/><path d="M 4.007 7.01 C 3.311 7.01 2.783 6.758 2.365 6.256 C 1.948 5.753 1.753 5.083 1.753 4.189 C 1.753 3.295 1.948 2.625 2.365 2.15 C 2.783 1.648 3.311 1.424 4.007 1.424 C 4.702 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.788 2.29 5.926 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.788 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.862 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.926 5.725 C 5.621 6.591 4.981 7.01 3.979 7.01 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="HetImuuV4" transform="translate(59.265 3.128)" width="7.735226155870485px"/><path d="M 6.872 3.268 L 2.643 3.268 L 2.643 2.681 C 2.643 2.206 2.754 1.871 2.949 1.676 C 3.144 1.508 3.478 1.396 3.923 1.396 L 3.923 0 C 2.921 0 2.17 0.223 1.697 0.642 C 1.196 1.061 0.946 1.759 0.946 2.681 L 0.946 3.268 L 0 3.268 L 0 4.636 L 0.946 4.636 L 0.946 11.422 L 2.643 11.422 L 2.643 4.636 L 5.203 4.636 L 5.203 11.422 L 6.872 11.422 Z" fill="rgb(255, 255, 255)" height="11.422308710362525px" id="Xc4NeSznw" transform="translate(50.863 0)" width="6.872402238697973px"/></g></svg>)


16 min read time
AI Summary by Centific
Turn this article into insights
with AI-powered summaries
Topics

Eivy Cedeno Torres
Kamwai Chan
Kriti Banka
Leela Krishna
Mangesh Damre

Ahmed Abdellah
Alex Cho
Emily Shen
Every robotics team has heard this story:
Months of work go into building a simulation environment — physics engines tuned to perfection; domain randomization cranked up, reward functions carefully shaped.
The policy achieves near-perfect task success in sim.
Then it’s transferred to real hardware.
The robot drops the object on the first try.
We measured this pattern directly at Centific. We built a Dexterous Manipulation Benchmark using simulated multi-fingered hands (16 degrees of freedom, 4 articulated fingers), then compared it against over 1,400 real teleoperated episodes from Unitree’s G1 humanoid robot across 29 task datasets — stacking blocks, pouring liquids, folding towels, cleaning tables, organizing tools, packaging cameras, and more.
1,400+ real episodes: the dataset that exposed the gap
Unitree Robotics, the manufacturer of the G1 humanoid, published a large-scale teleoperation dataset (DiverseManip) on HuggingFace, collected by human operators wearing VR headsets and controlling the G1’s arms and grippers in real time. This dataset spans single-arm and dual-arm tasks across three different end-effectors:
End-Effector | DOF | Type | Tasks Covered |
Unitree Dex1 | 1-DOF | Simple parallel gripper (open/close) | Towel folding, table cleaning, tool organizing, block stacking |
Unitree Dex3 | 28-DOF | Multi-fingered dexterous hand | Block stacking, pouring, camera packaging, object placement |
BrainCo Revo 2 | 6-DOF per hand | Anthropomorphic dexterous hand | Rubik's cube grasping, Oreo pickup, precision tasks |
This dataset gave us the real-world ground truth to benchmark against simulation. But it also revealed a critical limitation: the data was collected using standard VR controllers with basic IK retargeting. This method systematically destroys the most valuable signals in teleoperation data. This limitation is exactly what N1 Robotics’ neural retargeting technology is designed to solve.

Figure 1: Unitree G1 dexterous manipulation — dual-arm robot performing Rubik's Cube grasping and precision object manipulation tasks across the three end-effector configurations used in Centific’s benchmark.

Figure 2: Unitree G1 humanoid robot performing block manipulation tasks — the same robot platform used across all 29 datasets in Centific’s B4 Dexterous Manipulation Benchmark.
The numbers that opened our eyes
We measured four core metrics across simulation and real-world teleoperation. The results were unambiguous:
Metric | What it measures | Simulation | Real teleoperation | Gap |
Task Success Rate | Did the robot complete the task? | ~95% | ~83% | ~1.1x |
Manipulation Accuracy | How precise was object placement? | ~99% | ~68% | ~1.5x |
Grasp Quality | Was the grasp stable and functional? | ~68% | ~47% | ~1.5x |
Grasp Adaptiveness | Did the robot adjust mid-task? | ~100% | ~2% | ~50x |
Across these metrics, simulation consistently reports near-perfect performance, while real-world results diverge by 1.5x to over 50x on the measures that determine whether a task succeeds in deployment.
The largest difference appears in grasp adaptiveness. Simulation reports constant adjustment, while real operators adapt roughly 2 out of every 100 frames. That result is not a weakness; it reflects how operators anticipate failure before it occurs, using wrist orientation, approach angle, and timing. A policy trained only in simulation does not learn those anticipatory strategies. Recent work from NVIDIA points in a similar direction. In introducing the CaP-X framework, Jim Fan, NVIDIA Director of AI & Distinguished Scientist, describes API-driven robotic systems in which perception, planning, and control are composed at runtime, allowing robots to solve certain manipulation tasks zero-shot without task-specific policy training. This approach shifts part of the problem from learning behavior in advance to assembling it during execution, reinforcing the limits of training-only approaches.
When expanded our analysis across all 29 datasets spanning three different end-effectors (Dex1, Dex3, and BrainCo Revo 2 hands), the strongest dataset showed simulation overestimating grasp adaptiveness by over 80x. Across the full benchmark, 26 out of 29 datasets passed all quality gates, confirming the robustness of our methodology.
Why teleoperation teaches what simulation cannot
These results point to a broader issue: simulation captures outcomes, but not how those outcomes are achieved. When a human teleoperates a robot through a manipulation task, like picking up a slippery bottle, threading a cable, handing a tool to a colleague, they capture details that simulation does not reproduce: the physics of contact as experienced through imperfect sensing and actuation.
Real contact is messy, and that’s the point
In simulation, when a fingertip contacts an object, the force is modeled as a clean vector computed from a friction cone. In reality, the fingertip deforms, surfaces vary at a micro level, and sensors introduce noise, drift, and delay. The operator responds to these conditions by increasing pressure or adjusting wrist orientation to stabilize the grasp.
Our benchmark showed this clearly: simulated grasps scored higher by the simulator’s own metric, but real teleoperated grasps, though “messier,” were perfectly functional. The teleoperator learned to work with imperfections. A sim-trained policy optimized for the wrong objective would fail.
Recovery is the most valuable signal
The most important moments in any manipulation episode are the failures: the fumbled pickup, the object sliding mid-transfer, the awkward re-grasp. The most important moments in any manipulation episode are the failures: the fumbled pickup, the object sliding mid-transfer, the awkward re-grasp. In simulation, failures are rare. In real tasks, recovery happens frequently and provides useful training data. In our teleoperation dataset, nearly one in four episodes included at least one grasp-regrasp cycle. Every one of those is a lesson simulation cannot provide.
In our teleoperation dataset, nearly one in four episodes included at least one grasp-regrasp cycle. Every one of those is a lesson simulation cannot provide.
Teleoperation is grounded in physical reality
Two of our benchmark task types, in-hand rotation and self-correction via finger gaiting, had zero matching episodes in the real dataset. Why? Not because the robot couldn’t attempt them, but because a simple gripper physically cannot rotate an object in-hand using finger gaiting. Simulation lets you define any task; reality constrains which tasks are possible with a given end-effector. Teleoperation data is honest. It contains only what the hardware can actually do.
These results show that teleoperation data is not a substitute for simulation, but a reference point for it. Simulation approximates task outcomes, but it misses the contact dynamics that determine real-world success, often by an order of magnitude on key metrics.
What Centific built: the most comprehensive dexterity benchmark in the industry
To quantify this mismatch, Centific built a benchmark that compares simulation and real-world performance directly. The benchmark measures how large the difference is, where it appears, and what drives it across tasks, datasets, and end-effectors.
A benchmark engineered from the ground up
Centific’s Robotics & Physical AI team designed and executed the B4 Dexterous Manipulation Benchmark spanning 29 real-world task datasets, over 1,400 teleoperated episodes, three different dexterous end-effectors (Unitree Dex1, Dex3, and BrainCo Revo 2), and a simulated Allegro hand baseline. This experiment covered:
Household tasks (folding towels, cleaning tables).
Precision tasks (pouring medicine, mounting cameras).
Logistics tasks (packing boxes, organizing tools).
Bimanual coordination (dual-arm cleaning, dishwasher loading).
No one in the industry had systematically measured the sim-to-real dexterity gap across so many tasks, end-effectors, and episodes. Centific’s benchmark is the first to put hard numbers on what the field has long suspected.
Centific’s technical capabilities
Building this benchmark required deep robotics engineering across multiple disciplines. Here is what the Centific team designed, built, and validated:
Capability | What Centific built | Why it matters |
4-Metric Evaluation Framework | TSR, DMS, GQS, GAR — four complementary metrics with pass/fail gates | Industry-first standardized way to measure dexterity quality |
29-Dataset Benchmark Pipeline | Ingest HuggingFace datasets, extract joint trajectories, compute metrics, generate reports | Reproducible, scalable evaluation across any teleoperation dataset |
IK Retargeting Engine | Cross-embodiment retargeting that normalizes Dex1/Dex3/BrainCo data to a common 16-DOF Allegro joint space | Enables fair comparison across different robot hands — revealed the 50x to 1.6x insight |
Neural Retargeting Architecture | Production-ready infrastructure for ML-based retargeting (WaldoRT-compatible) | Ready to integrate with n1 Robotics or any neural retargeting model |
Sim-to-Real Fine-tuning Pipeline | Alpha-annealing data mixer, asymmetric actor-critic (SAC), dual replay buffer with cross-trial recycling | Implements latest RL research for stable real-world policy fine-tuning |
Multi-Domain Benchmark Framework | 4 benchmark domains: Airport Contact (B1), PCB Assembly (B2), Egocentric Transfer (B3), Dexterous Manipulation (B4) | Extensible architecture — new domains plug in without breaking existing ones |
NVIDIA Cosmos Reason 2 Integration | Verification and error-correction pipeline powered by Cosmos Reason 2 video understanding | AI-powered quality assurance for robotic manipulation episodes |
The insight only this benchmark could reveal
The most important finding from Centific’s benchmark was not the ~50x gap itself. It was what happened when we applied retargeting: the gap collapsed from ~50x to under 2x. This proved that the massive raw gap was largely a measurement artifact caused by comparing 1-DOF grippers against 16-DOF simulated fingers. The true dexterity gap is much smaller, but it can only be seen through proper retargeting.
This result shows what retargeting changes. When joint spaces are aligned, the observed difference reflects actual behavior rather than differences in embodiment. It also shows that teleoperated data contains more useful information than raw comparisons suggest, because human operators encode stable grasp strategies before failure occurs.
This insight has direct commercial implications: it means the problem is solvable. With the right retargeting technology, like N1 Robotics’ WaldoRT, the remaining gap can be closed with far less data than anyone previously assumed. Centific's benchmark is the evidence base that makes this case quantitatively.
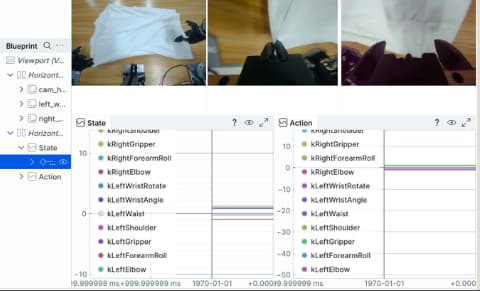
Figure 3: Centific’s data collection pipeline — robot joint state recordings showing State and Action telemetry across manipulation tasks in the B4 benchmark.
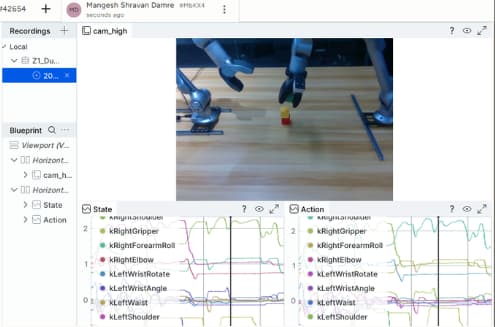
Figure 4: Centific benchmark episode — robot arm performing block manipulation task with real-time joint trajectory capture, part of Centific's 29-dataset evaluation framework.
The teleoperation bottleneck: why collecting data is still too slow
If teleoperation data is widely valuable, why isn’t everyone collecting it at scale? Because the current process is painfully slow.
Challenge | Industry Reality |
Setup time | 2-3 weeks of custom engineering to integrate XR trackers with a new robot |
Collection speed | ~50 episodes per hour after accounting for resets and operator fatigue |
Retargeting | Linear IK mapping that destroys the grasp intent the operator was trying to convey |
Cross-embodiment | Every new robot hand requires a custom retargeting pipeline from scratch |
The industry standard is linear Inverse Kinematics (IK) retargeting — mapping human joint angles to robot joint angles through geometric correspondence. This sounds reasonable, but it systematically destroys exactly the signals that make teleoperation data valuable.
When a human pinches an object between thumb and index finger, the IK mapper sees two joint angles. It maps them independently to the robot’s two corresponding joints. But the pinch isn’t about individual joint angles; it’s about the coordinated closure that creates force closure on the object. Linear IK strips away this coordination, the grasp intent, and the precision geometry. What remains is a lossy approximation that requires many more demonstrations to learn the same policy.
Neural retargeting: the breakthrough that changes everything
Here is where the pieces connect. Centific’s benchmark used Unitree’s G1 robot dataset, collected with VR headsets and basic IK retargeting. We found massive gaps, especially in grasp adaptiveness. What if the same Unitree G1 data was collected with a system that preserves grasp intent instead of destroying it?
That system exists. N1 Robotics’ Waldo is built for the same Unitree G1 humanoid that our benchmark is based on. But replaces the VR + IK retargeting pipeline with neural retargeting that faithfully captures what the human operator intended.
Same robot, better data: Waldo on the Unitree G1
Waldo is a complete dexterous teleoperation platform designed specifically for the Unitree G1 humanoid (29-DOF) with BrainCo Revo 2 hands (6-DOF per hand), the same robot and one of the same end-effectors in our benchmark. It includes finger-tracking gloves with EMF sensors, Vive trackers for 6-DOF wrist tracking, a pre-configured inference PC, and software that handles calibration, recording, and export out of the box.
Capability | Industry baseline | Waldo |
Setup time | 2-3 weeks | 15 minutes |
Collection speed | ~50 episodes/hr | ~200 episodes/hr |
End-to-end latency | Variable, often >200ms | <100ms |
Retargeting method | Linear IK (lossy) | WaldoRT neural mapping (preserves intent) |
Using Waldo for teleoperation results in a 4x speedup in data collection and a 100x reduction in setup time. For example, Unitree’s DiverseManip dataset, the same dataset Centific benchmarked, took an estimated 20 hours to collect using VR headsets. With Waldo on the same G1 robot, an equivalent dataset can be collected in roughly 5 hours, with higher fidelity per episode due to neural retargeting.
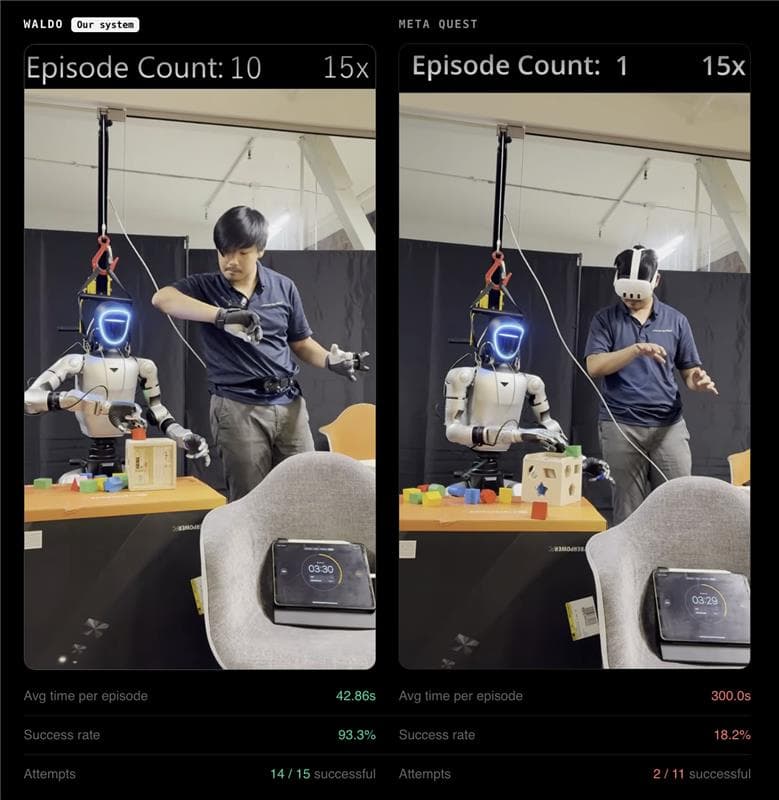
Figure 5: Waldo vs Meta Quest — side-by-side comparison. Waldo (left): Episode Count 4, Avg 42.86s per episode, 93.3% success rate, 14/15 successful. Meta Quest (right): Episode Count 1, Avg 300s per episode, 18.2% success rate, 2/11 successful. Same robot, same task, same time window.
Neural retargeting in action
Neural retargeting is the mechanism that makes teleoperation data usable for training.

Figure 6: WaldoRT Neural Retargeting in action — human hand pose (left) mapped to robot hand pose (right) using neural network inference at 1 kHz. The model preserves finger coordination and grasp intent that IK mapping destroys. This is the core technology that collapses the 50× gap to under 2×.
This figure shows how neural retargeting maps human hand motion to robot control in real time. The mapping preserves coordination across fingers and maintains grasp intent during execution.
N1 Robotics partnership: what this means for Centific
Centific is partnering with N1 Robotics to bring Waldo into our large-scale data collection pipeline. Key details from our partnership:
WaldoRT runs inference at 1 kHz: lightweight, fast, and scales identically from 6-DOF to higher DOF hands with zero latency increase
Setup takes under 30 seconds: push a pedal and data collection begins immediately
Time between episodes can be as short as 5 seconds, enabling rapid rinse-and-repeat collection loops
Inference PC ships pre-configured with an NVIDIA GPU, which is compatible with Centific’s Jetson Thor infrastructure
Multi-operator profiles are pre-saved: operators clock in ready to collect without hand retraining
Enterprise plan includes 100 hours per month of N1 Robotics managed operator time on Centific’s systems
Custom integration builds available for additional end-effectors and robot embodiments beyond humanoids
These capabilities make it possible to collect high-fidelity manipulation data quickly and consistently across operators, tasks, and robot configurations.
CaP-X: when frontier LLMs become robot controllers
A parallel development is reshaping how we think about robot control entirely. CaP-X (Coding as Policies), available at capgym.github.io, demonstrates that frontier large language models can control robots, without any robot-specific training, simply by writing executable control code from natural language task descriptions.
CaP-Agent0: zero-shot manipulation
CaP-Agent0 is a training-free coding agent evaluated across 100+ manipulation tasks spanning LIBERO-PRO, Robosuite, and BEHAVIOR. The findings:
Frontier models achieved over 30% average zero-shot success on manipulation, with no task-specific training
On LIBERO-PRO with position and instruction perturbations, state-of-the-art VLAs like OpenVLA and pi0 scored 0% across the board
Even the best VLA (pi0.5) reached only 13% average success on perturbed tasks
CaP-Agent0 reached 18% (better than the best VLA) without any training
These results show that training alone does not guarantee robustness, and that alternative approaches can outperform learned policies even without task-specific optimization.
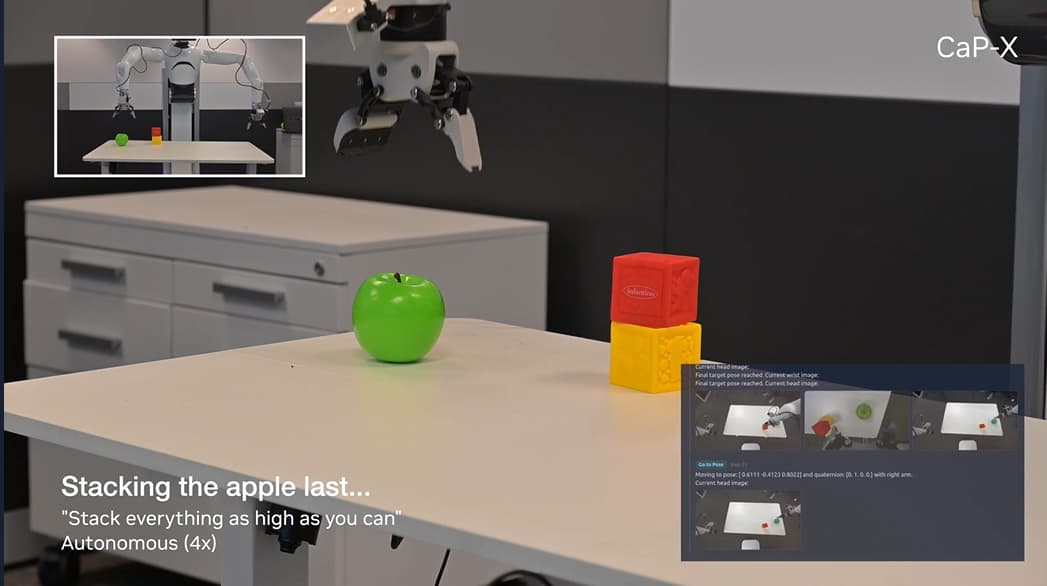
Figure 7: CaP-Agent0 in action: robot recognizes the affordance of stacking order, placing cubes before the round apple. The instruction: “Stack everything as high as you can.” Autonomous execution (4x speed). Source: capgym.github.io
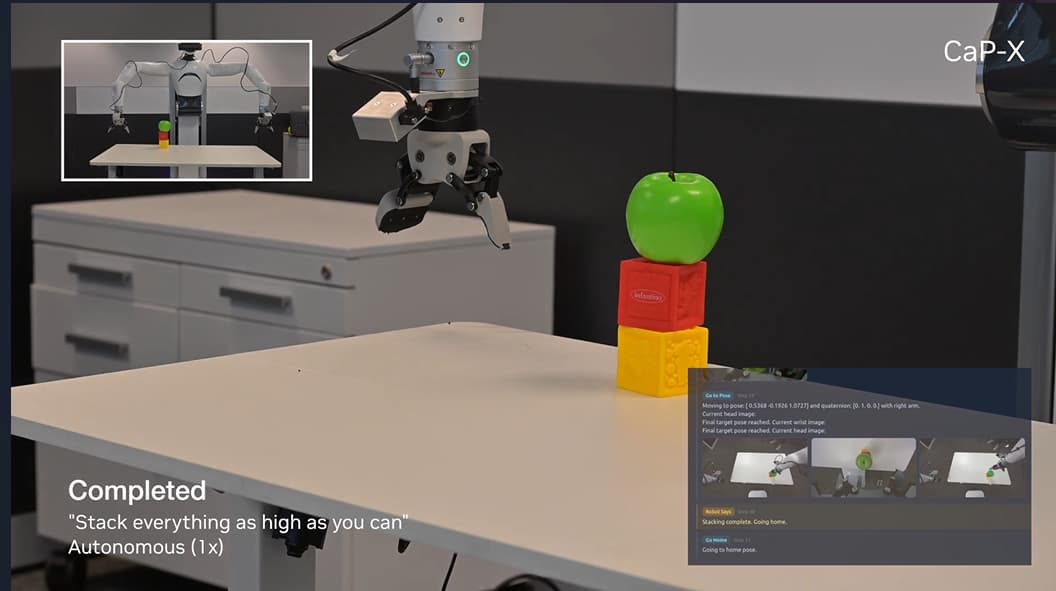
Figure 8: CaP-Agent0 task completed. Cubes stacked with apple on top, demonstrating embodied reasoning about object geometry without any task-specific training. Source: capgym.github.io
CaP-RL: code-based post-training
CaP-RL applies reinforcement learning directly to the coding agent. A 7B-parameter model (Qwen 2.5 Coder) jumped from 20% to 72% average success in simulation after just 50 training iterations. The learned policies then transferred to a real Franka robot (84% on cube lifting, 76% on cube stacking) with minimal sim-to-real gap.
Why CaP-X matters for this pipeline
CaP-X addresses the task generalization layer, allowing robots to handle novel instructions without retraining. When CaP-Agent0 generates task code and WaldoRT-collected episodes provide the fine-grained manipulation signal, they cover complementary failure modes. CaP-X handles novel instructions and task reasoning; WaldoRT handles the physical contact fidelity that code alone cannot capture.
The complete pipeline: from simulation to deployment
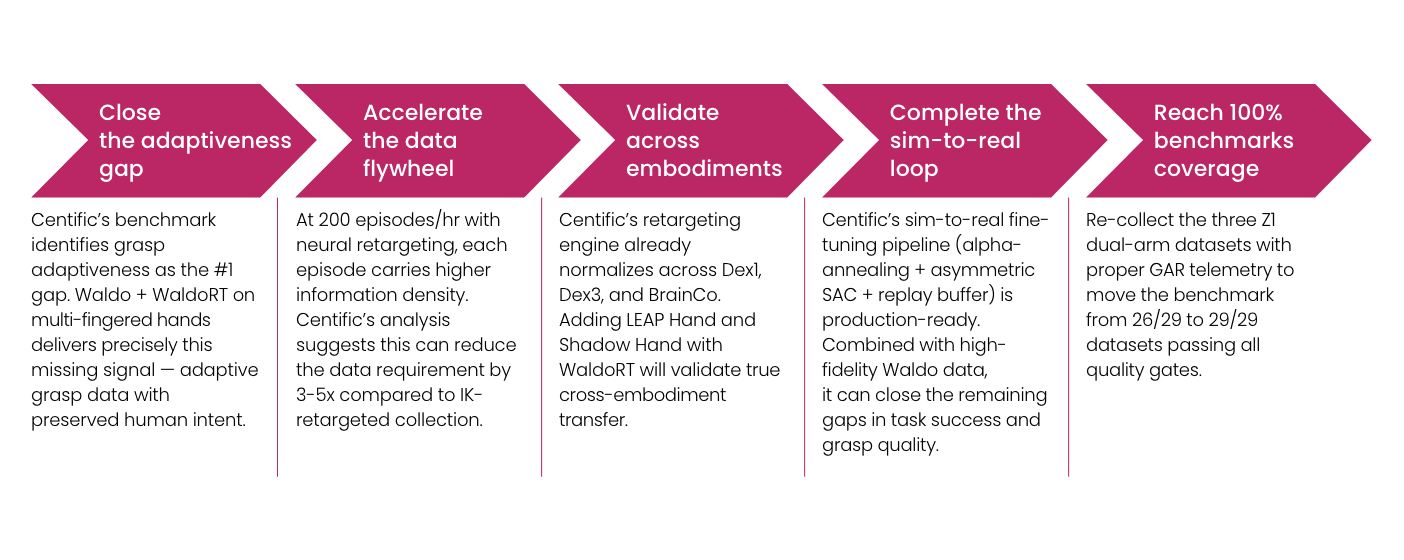
Our benchmark, combined with recent advances in data-efficient reinforcement learning, points to a five-phase architecture for closing the sim-to-real dexterity gap:

Figure 9: Five-phase pipeline for closing the sim-to-real dexterity gap — Phase 1: Portable Data Collection → Phase 2: Neural Retargeting (WaldoRT) → Phase 3: Simulation Pre-training → Phase 4: Real-World Fine-tuning → Phase 5: Deployment with Human-in-the-Loop Correction.
Phase 1: portable data collection
Capture human manipulation with wearable motion-capture rigs (finger tracking gloves + wrist trackers). No robot needed during collection. Approaches like DexCap (RSS 2024) achieve 3x the speed of traditional teleoperation at a fraction of the cost. Critically, store all attempts, including failures, because mixed-quality data provides better state-space coverage than expert-only demonstrations.
Phase 2: neural retargeting
Map human hand motions to robot hand commands using learned models like WaldoRT. This preserves grasp intent, force closure, and finger coordination at 1-2ms per frame, compatible across different end-effectors without custom engineering per robot.
Phase 3: simulation pre-training
Train policies in massively parallel simulation, with thousands of environments running simultaneously, to learn task structure such as approach trajectories, finger coordination patterns, and basic manipulation sequences. Our benchmark shows that simulation transfers task-level structure well, with an approximately 1.1x gap in success rate, even though contact-level details remain poor.
Phase 4: real-world fine-tuning
Fine-tune sim-pretrained policies on real teleoperation data using stabilized RL techniques: alpha-annealing data mixing (gradually shifting from sim to real data), asymmetric actor-critic updates, and warm-start episodes. Research shows these techniques prevent the catastrophic forgetting that typically destroys sim-pretrained policies during real-world fine-tuning.
Phase 5: deployment + human-in-the-loop correction
Deploy the fine-tuned policy with live Waldo teleoperation for human-in-the-loop correction. When the policy fails, the operator takes over, generating the hardest and most valuable training data. At 200 episodes per hour, correction data accumulates rapidly. Each cycle closes the gap further.
Centific + neural retargeting: the roadmap
Centific’s benchmark provides evidence of where simulation falls short and how large the gap remains in real-world performance. The five-phase pipeline defines the architecture. Neural retargeting platforms like n1 Robotics’ Waldo provide the tooling. Together, they form a concrete roadmap for building the data infrastructure that next-generation robotics demands.
Why this matters for foundation models
The next frontier in robotics is dexterous foundation models: vision-language-action (VLA) models that can reason about finger placement, contact forces, and in-hand manipulation from natural language instructions. Models like RT-2, Octo, and pi0 have shown this is possible for simple grippers. But extending to multi-fingered dexterity requires millions of teleoperated episodes with rich grasp data, which is the kind of data that Centific’s pipeline is designed to produce and that neural retargeting makes feasible to collect at scale.
The roadmap
Implications for Dexterous Manipulation Training
The gap between simulated and real-world dexterous manipulation is a fundamental measure of how much real-world contact physics matters and how much of that knowledge can only come from human-guided teleoperation.
Simulation gives you task structure. Teleoperation gives you contact truth. Neural retargeting ensures that contact truth is preserved when mapping human motion to robot control.
Dimension | Simulation | Teleoperation | Winner |
Task success | Higher scores | Harder, but grounded in reality | Teleop |
Manipulation accuracy | Near-perfect | Imperfect but true | Teleop |
Grasp quality | Optimized for wrong metric | Messier, but functional | Teleop |
Grasp adaptiveness | Scripted, artificial | Anticipatory, human-intelligent | Teleop |
Recovery behaviors | Grasps don't fail in sim | 1 in 4 episodes includes recovery | Teleop |
Data fidelity | Perfect but wrong | Imperfect but true | Teleop |
Setup cost (with Waldo) | GPU cluster + months | ~$12K hardware + 15 min | Teleop |
The implications extend beyond model performance. The constraint is not simulation quality alone, but the data used to train policies. Robotics companies that invest in teleoperation infrastructure and collect high-fidelity manipulation data will have an advantage, because their models are trained on the contact behavior that determines real-world outcomes.
Are your ready to get
modular
AI solutions delivered?
Connect data, models, and people — in one enterprise-ready platform.
Latest Insights



Connect with Centific
Updates from the frontier of AI data.
Receive updates on platform improvements, new workflows, evaluation capabilities, data quality enhancements, and best practices for enterprise AI teams.